预约演示
更新于:2025-09-09
NeoCura Bio-Medical Technology Co., Ltd.
更新于:2025-09-09
概览
标签
肿瘤
感染
消化系统疾病
治疗性疫苗
mRNA疫苗
预防性疫苗
疾病领域得分
一眼洞穿机构专注的疾病领域

技术平台
公司药物应用最多的技术
靶点
公司最常开发的靶点
关联
靶点 |
作用机制 |
在研机构 |
原研机构 |
在研适应症 |
非在研适应症 |
最高研发阶段 |
首次获批国家/地区 |
首次获批日期 |

靶点 |
作用机制 |
在研机构 |
原研机构 |
在研适应症 |
非在研适应症 |
最高研发阶段 |
首次获批国家/地区 |
首次获批日期 |
靶点 |
作用机制 |
在研机构 |
原研机构 |
在研适应症 |
非在研适应症 |
最高研发阶段 |
首次获批国家/地区 |
首次获批日期 |
NCT06353646
Efficacy and Safety Trial of XH001 (Neoantigen Cancer Vaccine) Sequential Combination With Immunocheckpoint Inhibitor and Chemotherapy in Adjuvant Therapy for Patients With Resected Pancreatic Cancer
NCT05940181
A Safety and Efficacy Study of XH001 (Neoantigen Cancer Vaccine) Combined With Sintilimab Injection in Advanced Solid Tumors
NCT05359354
A Dose-Escalation and Dose-Expansion Study Evaluating the Safety and Efficacy of Personalized Neoantigen Vaccine in Advanced Solid Tumors
100 项与 深圳市新合生物医疗科技有限公司 相关的临床结果
登录后查看更多信息
登录后查看更多信息
Vaccines
Development of a Cationic Polymeric Micellar Structure with Endosomal Escape Capability Enables Enhanced Intramuscular Transfection of mRNA-LNPs
Article
作者: Wang, Yi ; Shang, Hongtao ; Chen, Xiaomeng ; Zhao, Zhao ; Cao, Jingyi ; Shao, Han ; Deng, Siyuan ; Pang, Lingjin
Background/Objectives: The endosomal escape of lipid nanoparticles (LNPs) is crucial for efficient mRNA-based therapeutics. Here, we present a cationic polymeric micelle (cPM) as a safe and potent co-delivery system with enhanced endosomal escape capabilities. Methods: We synthesized a cationic and ampholytic di-block copolymer, poly (poly (ethylene glycol)4-5 methacrylatea-co-hexyl methacrylateb)X-b-poly(butyl methacrylatec-co-dimethylaminoethyl methacrylated-co-propyl acrylatee)Y (p(PEG4-5MAa-co-HMAb)X-b-p(BMAc-co-DMAEMAd-co-PAAe)Y), via reversible addition–fragmentation chain transfer polymerization. The cPMs were then formulated using the synthesized polymer by the dispersion–diffusion method and characterized by dynamic light scattering (DLS) and cryo-transmission electron microscopy (CryoTEM). The membrane-destabilization activity of the cPMs was evaluated by a hemolysis assay. We performed an in vivo functional assay of firefly luciferase (Fluc) mRNA using two of the most commonly studied LNPs, SM102 LNP and Dlin-MC3-DMA LNPs. Results: With a particle size of 61.31 ± 0.68 nm and a zeta potential of 37.76 ± 2.18 mV, the cPMs exhibited a 2–3 times higher firefly luciferase signal at the injection site compared to the control groups without cPMs following intramuscular injection in mice, indicating the high potential of cPMs to enhance the endosomal escape efficiency of mRNA-LNPs. Conclusions: The developed cPM, with enhanced endosomal escape capabilities, presents a promising strategy to improve the expression efficiency of delivered mRNAs. This approach offers a novel alternative strategy with no modifications to the inherent properties of mRNA-LNPs, preventing any unforeseeable changes in formulation characteristics. Consequently, this polymer-based nanomaterial holds immense potential for clinical applications in mRNA-based vaccines.
Nature communications1区 · 综合性期刊
Inadequate structural constraint on Fab approach rather than paratope elicitation limits HIV-1 MPER vaccine utility
1区 · 综合性期刊
ArticleOA
作者: Kim, Mikyung ; Donius, Luke ; Li, Xiaolong ; Richter, Hannah ; Reinherz, Ellis L ; Hwang, Wonmuk ; Walz, Thomas ; Wang, Yi ; Tan, Kemin ; Seaman, Michael S ; Khan, Rafiq Ahmad ; Kaku, Yu ; Chen, Junjian
Abstract:
Broadly neutralizing antibodies (bnAbs) against HIV-1 target conserved envelope (Env) epitopes to block viral replication. Here, using structural analyses, we provide evidence to explain why a vaccine targeting the membrane-proximal external region (MPER) of HIV-1 elicits antibodies with human bnAb-like paratopes paradoxically unable to bind HIV-1. Unlike in natural infection, vaccination with MPER/liposomes lacks a necessary structure-based constraint to select for antibodies with an adequate approach angle. Consequently, the resulting Abs cannot physically access the MPER crawlspace on the virion surface. By studying naturally arising Abs, we further reveal that flexibility of the human IgG3 hinge mitigates the epitope inaccessibility and additionally facilitates Env spike protein crosslinking. Our results suggest that generation of IgG3 subtype class-switched B cells is a strategy for anti-MPER bnAb induction. Moreover, the findings illustrate the need to incorporate topological features of the target epitope in immunogen design.
100 项与 深圳市新合生物医疗科技有限公司 相关的药物交易
登录后查看更多信息
100 项与 深圳市新合生物医疗科技有限公司 相关的转化医学
登录后查看更多信息
组织架构
使用我们的机构树数据加速您的研究。
登录
或

管线布局
2025年09月21日管线快照
管线布局中药物为当前组织机构及其子机构作为药物机构进行统计,早期临床1期并入临床1期,临床1/2期并入临床2期,临床2/3期并入临床3期
药物发现
3
9
临床前
临床申请
1
1
临床1期
其他
7
登录后查看更多信息
当前项目
登录后查看更多信息
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
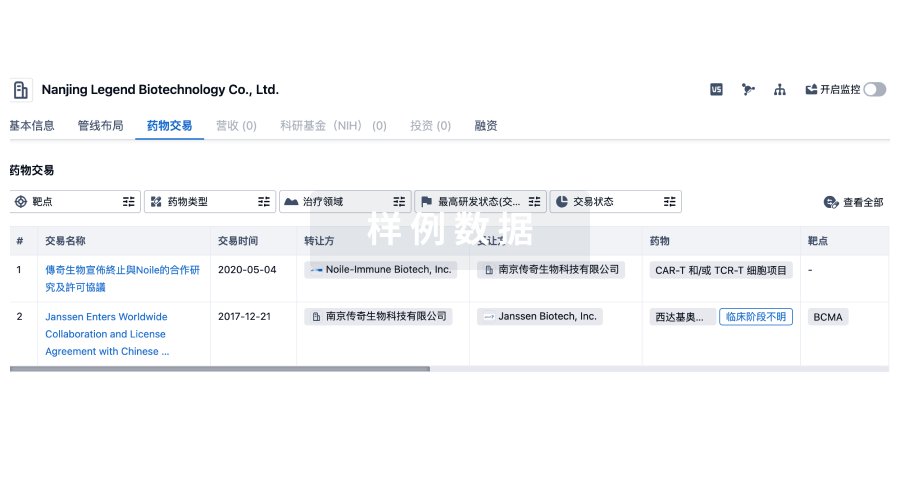
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
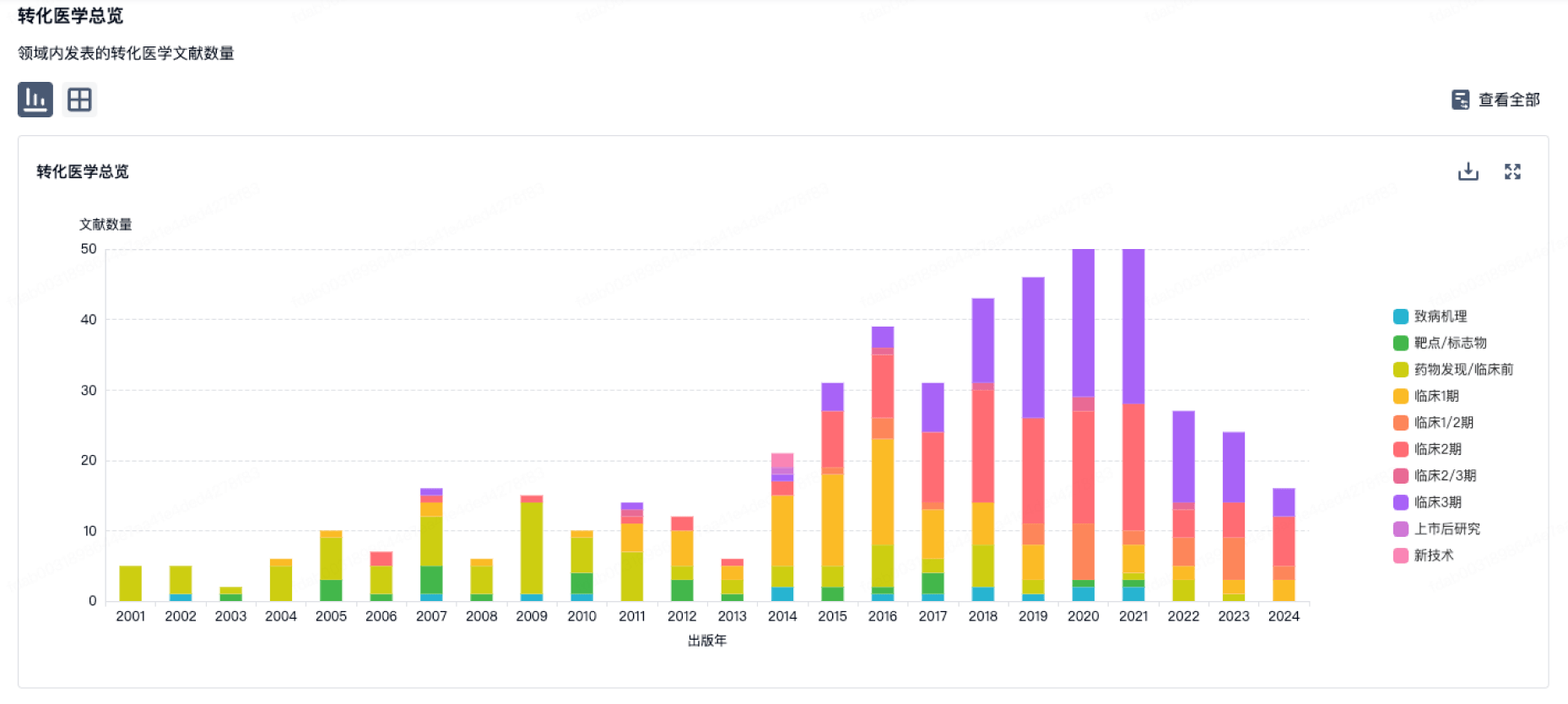
营收
使用 Synapse 探索超过 36 万个组织的财务状况。
登录
或
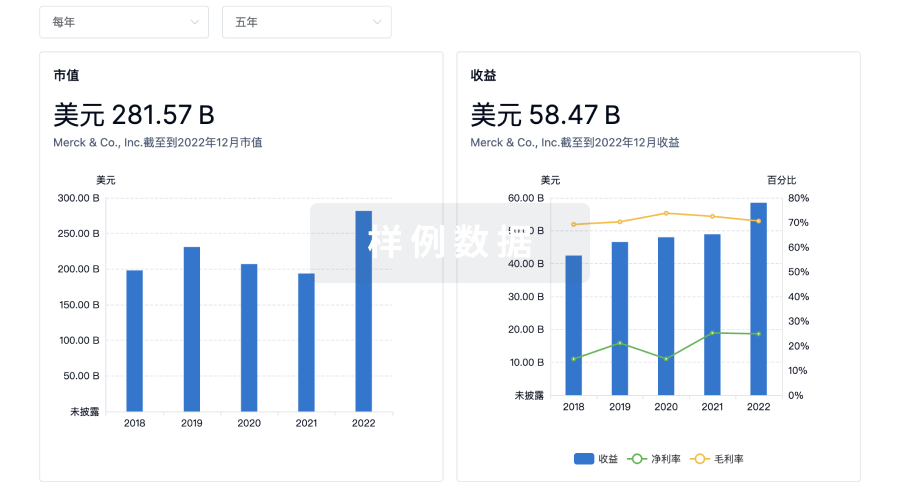
科研基金(NIH)
访问超过 200 万项资助和基金信息,以提升您的研究之旅。
登录
或
投资
深入了解从初创企业到成熟企业的最新公司投资动态。
登录
或
融资
发掘融资趋势以验证和推进您的投资机会。
登录
或
Eureka LS:
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用