预约演示
更新于:2025-05-07
Dystonia 18
18型肌张力障碍
更新于:2025-05-07
基本信息
别名 DYSTONIA 18、DYSTONIA 18 (disorder)、DYT18 + [13] |
简介 A form of paroxysmal dyskinesia with characteristics of painless attacks of dystonia of the extremities triggered by prolonged physical activities. The prevalence is unknown but 20 sporadic cases and 9 families have been described to date. The attacks last between 5 minutes and 2 hours and are typically restricted to the exercised limbs. The dystonic movements are usually bilateral and are aggravated by cold, psychological stress, fatigue and lack of sleep. The pathophysiology is still unknown but some familial cases were found to be associated with mutations in the SLC2A1 gene (1p34.2). Sporadic and familial cases with autosomal dominant mode of inheritance have been reported. |
关联
靶点 |
作用机制 |
在研机构 |
原研机构 |
在研适应症 |
非在研适应症 |
最高研发阶段 |
首次获批国家/地区 |
首次获批日期 |

靶点 |
作用机制 |
在研机构 |
原研机构 |
在研适应症 |
非在研适应症 |
最高研发阶段 |
首次获批国家/地区 |
首次获批日期 |


NCT06386159
Clinical Application of Comprehensive Intervention Scheme for Post-extubation Dysphagia Based on Neuroregulatory Mechanism
JPRN-UMIN000046443
Evaluation of the usefulness of a swallowing electrical stimulator in maintaining swallowing function in patients after extubation: a randomized controlled trial - Evaluation of the usefulness of a swallowing electrical stimulator in maintaining swallowing function in patients after extubation: a randomized controlled trial
NCT04112862
Effects of Sodium Lactate Infusion in Patients With Glucose Transporter 1 Deficiency Syndrome (GLUT1DS)

100 项与 18型肌张力障碍 相关的临床结果
登录后查看更多信息
100 项与 18型肌张力障碍 相关的转化医学
登录后查看更多信息
登录后查看更多信息
2025-06-01Microbial Pathogenesis
Molecular characterization of porcine epidemic diarrhea virus in Sichuan from 2023 to 2024
Article
作者: Yan, Wenjun ; Yang, Xin ; Fan, Hua ; Xie, Bo
2025-06-01Computer Methods and Programs in Biomedicine
Global-Local Transformer Network for Automatic Retinal Pathological Fluid Segmentation in Optical Coherence Tomography Images
Article
作者: Chen, Yuyang ; Sheng, Xinyu ; Wei, Hao ; Li, Feng ; Zou, Haidong ; Huang, Song
2025-05-01Acta Ophthalmologica
Correlation of retinal fluid and photoreceptor and RPE loss in neovascular AMD by automated quantification, a real‐world FRB! analysis
Article
作者: Schmidt‐Erfurth, Ursula ; Reiter, Gregor S. ; Bogunovic, Hrvoje ; Leigang, Oliver ; Mares, Virginia ; Gumpinger, Markus ; Barthelmes, Daniel ; Nehemy, Marcio B.
2024-04-06
2024-03-21
疫苗引进/卖出
2024-01-05
疫苗临床研究诊断试剂
分析
对领域进行一次全面的分析。
登录
或
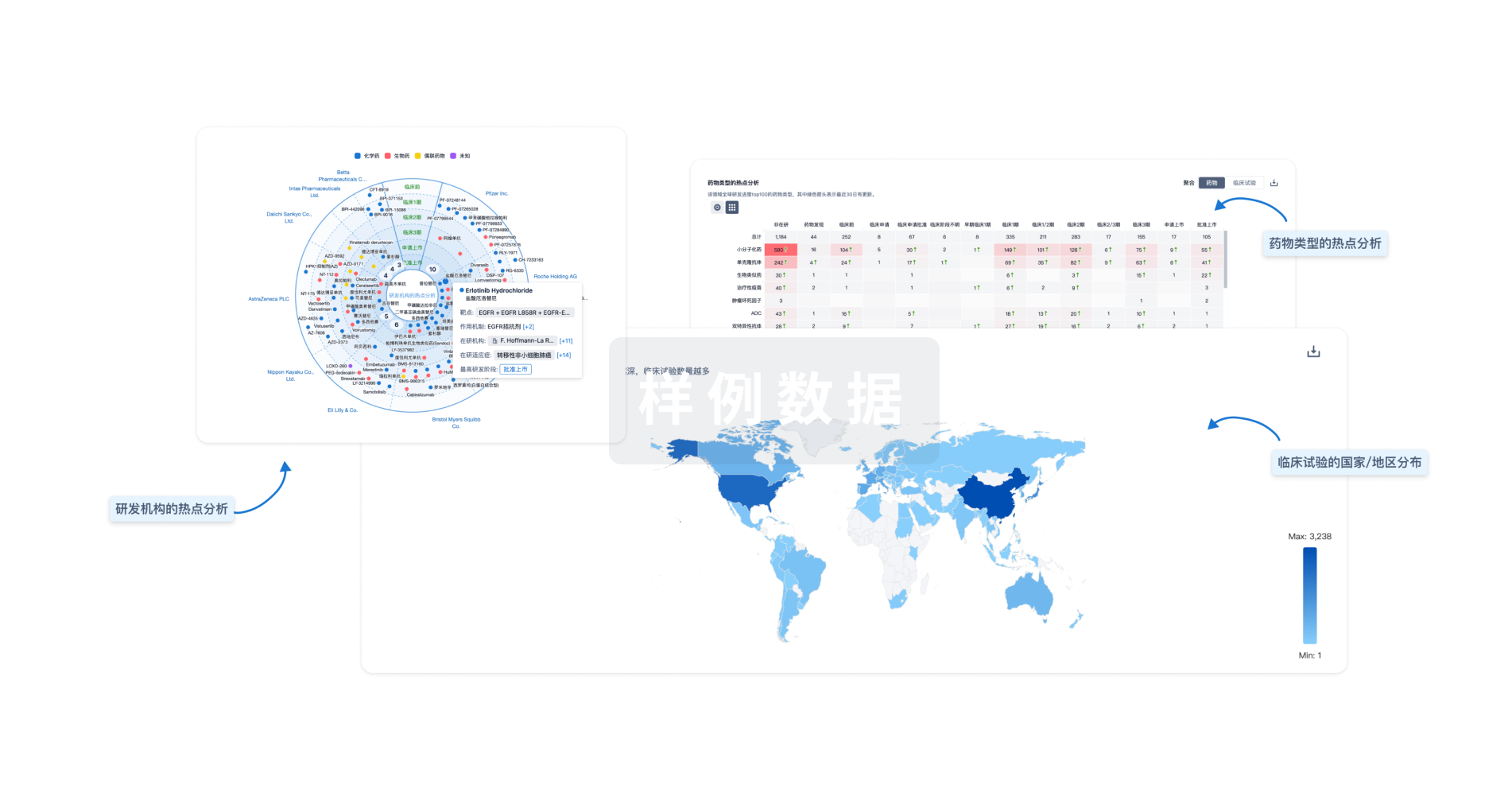
Eureka LS:
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用