更新于:2024-11-01
Meta Centre
更新于:2024-11-01
概览
关联
100 项与 Meta Centre 相关的临床结果
登录后查看更多信息
0 项与 Meta Centre 相关的专利(医药)
登录后查看更多信息
1
项与 Meta Centre 相关的文献(医药)Biomedicines
Anti-Aging Drugs and the Related Signal Pathways
Review
作者: Liu, Chenyu ; Zhou, Wenzhao ; Yang, Ruigang ; Sun, Qiang ; Jiang, Shengrong ; Niu, Zubiao ; Du, Nannan ; Gao, Lihua
23
项与 Meta Centre 相关的新闻(医药)2024-10-30
·美通社
加利福尼亚州雷德伍德城
2024年10月30日
/美通社/ -- 陈天桥雒芊芊脑科学研究院(TCCI)内部人工智能团队凭借对大脑和记忆的深刻理解,在人工智能领域取得了重大突破。他们自主研发的OMNE多智能体框架在GAIA(通用人工智能助手)基准测试排行榜(
https://huggingface.co/spaces/gaia-benchmark/leaderboard
)上夺得首位,该排行榜由Meta AI、Hugging Face和Hugging Face的AutoGPT共同发起。 OMNE的表现优于包括微软研究院(Microsoft Research)在内的一些世界领先机构的框架。 这一成就基于TCCI多年的大脑研究成果,赋予智能体长期记忆(LTM)能力,使得框架能够进行更深层次、更缓慢的思考,并在复杂问题解决中增强大型语言模型(LLM)的决策能力。
Tianqiao_and_Chrissy_Chen_Institute__Institute_was_created_in_2016_by_Tianqiao_Chen_and_Chrissy_Luo
这一里程碑是自该研究院创始人、前中国科技巨头陈天桥去年宣布"All-In AI战略"以来,TCCI人工智能团队的一项重大成就。
OMNE
目前的
总体成功率达到40.53%
,在性能上超
过了Meta
、微
软、Hugging Face
、普林斯
顿大学、香港大学、英国人工智能安全研究所以及百川等提交的成果。
与此相比,配
备插件的GPT-4
的成功率
仅为15%
。
GAIA是多智能体智能领域中最严格的数据集之一,能够在其排行榜上位居首位,彰显了TCCI在人工智能领域的深厚专业知识以及拓展创新边界的能力。
OMNE是一个基于长期记忆(LTM)的多智能体协作框架。 每个智能体具有相同且独立的系统结构,能够自主学习和理解完整的世界模型,从而独立理解其环境。 基于LTM的多智能体协同系统使人工智能系统能够实时适应个体行为变化,优化任务规划和执行,促进个性化、高效的自我进化。
这一突破是长期记忆机制的融合,大大缩小了MCTS的搜索空间,提高了对复杂问题的决策能力。
通
过引入更高效的逻辑推理,OMNE
不
仅提升了单个智能体的智能水平,还通过优化协作机制显著增强了多智能体系统的整体能力。
这种增强的灵感来自对人类大脑皮层柱状结构的研究。
作
为大脑认知和行为功能的基本单位,皮质柱通过复杂的协作机制实现信息处理。
通
过加强单个智能体之间的协作,人工智能模型可能逐渐展现出认知能力,构建起内部表征模型,并最终推动系统整体智能的飞跃。
"我们对OMNE荣登GAIA排行榜榜首感到无比自豪。" TCCI人工智能团队负责人表示。 "这一成就展示了利用长期记忆推动人工智能自我进化和解决现实世界问题的巨大潜力。 我们认为,推进长期记忆和人工智能自我进化的研究对于人工智能技术的持续发展和实际应用至关重要。"
招聘:
AItalents@cheninstitute.org

2024-10-25
SAN FRANCISCO, Oct. 25, 2024 /PRNewswire/ -- Hospital quality reporting platform Pharos announced today the close of its oversubscribed $5M seed round led by Felicis with participation from General Catalyst, Moxxie and Y Combinator. Pharos will use the funds to grow its engineering team, allowing customers to report to new clinical quality registries and measure a wider range of process metrics.
Founded in 2024 by a team of clinicians and AI researchers, Pharos automates clinical quality reporting for hospitals, enabling submission to state and national quality registries without manual abstraction.
Additionally, by enabling automatic extraction of custom process metrics, Pharos helps quality teams identify the process failures that are contributing to patient harm, enabling action on issues like sepsis mortality, hospital-acquired infections, and pressure ulcers.
"Today, hospitals spend thousands of hours manually abstracting metrics from unstructured medical records to fulfill registry reporting requirements and understand patient safety events," said Felix Brann, CEO and co-founder of Pharos. "This manual work is expensive, pulls clinical staff away from the front-line, and means that hospital teams get data long after patients are discharged. Pharos automates abstraction for quality reporting, letting hospitals report to new registries and track metrics that matter to them without adding to clinical reviewer backlogs. We give teams data in real-time, letting them take action on process gaps before they turn into patient harm."
Brann was previously VP of Data Science at Vital. At Vital, he and Matthew Jones, CTO and co-founder, deployed live predictive AI into over 70 hospitals, integrating with every major electronic health record vendor. While trialing a sepsis model, they recognized the value AI could provide to hospital quality teams. Brann was previously VP of Quantitative Research at JP Morgan. He has published papers in major medical journals on sepsis prediction and medical record summarization using LLMs. Jones worked on the Orion Health EHR and grew M2X from inception to international expansion.
The team is also joined by Dr. Alex Clarke, Head of Research, an MD with a PhD in Artificial Intelligence from Imperial College London. He worked as a medical AI researcher at Meta and experienced the time-consuming medical abstraction process firsthand during his time as a resident doctor.
"When we met the Pharos team and learned about their deep expertise in both healthcare and AI, we knew we had to work with them," said Ryan Isono, Partner at Felicis. "The mundane areas of healthcare administration make up nearly $1 trillion in spend annually. Pharos uses AI to automate the manual process of hospital quality reporting, which is dramatically underinvested in and can have a huge impact on not just savings but patient safety, too. The platform automates manual data abstraction from medical records, enabling hospitals to identify and resolve process failures in real time. With their experience deploying AI in 70+ hospitals and publishing relevant research, we couldn't imagine a better team to tackle this problem."
Numerous studies have shown that access to data and adherence to processes can have significant impacts on patient safety. The American College of Surgeons estimates that 60% of current surgical site infections are preventable with good process, and the same is true for many other patient harm events. Pharos' mission is to help hospitals prevent this harm before it happens.
You can learn more about the company and the technology at
Media Contact
Ellie Tippett, KCPR
[email protected]
About Pharos
Pharos automates hospital quality reporting and helps staff identify the root causes of avoidable harm. Their AI automates chart abstraction for quality registries and process adherence measures, reducing staff burden and providing data instantly, rather than weeks after discharge.
You can't improve what you can't measure. Pharos enables quality teams to see where and why safety issues are happening in real time, enabling them to take action on issues like sepsis mortality, hospital acquired infections and pressure ulcers.
Pharos is a mission-driven team of clinicians and AI researchers from Meta, J.P. Morgan and Orion Health. They recently raised $5m in funding from Felicis, General Catalyst, Moxxie and Y Combinator to enable hospital quality teams with AI.
About Felicis
Founded in 2006, Felicis is a venture capital firm investing in companies reinventing core markets, as well as those creating frontier technologies. Felicis focuses on early-stage investments and currently manages over $3B in capital across 9 funds. The firm is an early backer of more than 45 companies valued at $1B+. More than 100 of its portfolio companies have been acquired or gone public, including Adyen (IPO), Credit Karma (acq by Intuit), Cruise (acq by General Motors), Fitbit (IPO), Guardant Health (IPO), Meraki (acq by Cisco), Ring (acq by Amazon), and Shopify (IPO). The firm is based in Menlo Park and San Francisco in California. Learn more at felicis.com.
SOURCE Pharos
WANT YOUR COMPANY'S NEWS FEATURED ON PRNEWSWIRE.COM?
440k+
Newsrooms &
Influencers
9k+
Digital Media
Outlets
270k+
Journalists
Opted In
GET STARTED

2024-10-18
David Baker has been pushing the limits of designing proteins for decades.
The computational biologist started developing software, called Rosetta, to study and design proteins in the 1990s. He’s now the director of the University of Washington’s Institute for Protein Design.
The Baker lab has become a prolific producer of not just AI models and scientific articles, but of big-swinging startups. He has co-founded 21 companies, most notably
Xaira Therapeutics
, backed by $1 billion-plus to turn his lab’s research into drugs.
Baker
won the Nobel Prize in Chemistry
last week for his protein work. He sat down with
Endpoints News
to chat at our inaugural AI Day. This conversation has been substantially edited for clarity and length.
Andrew Dunn:
How’s it feel to add Nobel laureate to your list of titles?
David Baker:
It’s been a little crazy. I don’t think I’ve ever been so strung out in my life. I’m looking forward to things calming down a bit.
Dunn:
Why is designing proteins from scratch such a big deal?
Baker:
We know proteins can carry out an amazing array of functions, evolved over millions or billions of years to solve the problems. You think about photosynthesis or all the ion channels in our brains that mediate cognition. We work just amazingly well because we have amazing proteins.
There are new problems today. In medicine, we live longer, so there are new diseases. There’s always potential for new pandemic viruses. And outside of medicine, we’re heating up the planet and polluting it.
Some of these probably would be solved if there was evolutionary pressure and we had another 100 million years to wait. The promise of protein design is to be able to design new proteins that solve current problems as well as proteins in nature solve problems that were relevant during natural selection.
Dunn:
How’d you first get interested in protein design, particularly with the computational focus?
Baker:
I wasn’t the first. Bill DeGrado showed you could do
de novo
design and Steve Mayo showed you could use computers to redesign the sequence of proteins. Brian Kuhlman, when he came to my lab as a postdoc, had the idea of doing flexible backbone protein design.
When I arrived at UW, we had been doing experiments to understand how proteins fold and incorporating what we learned in the first version of Rosetta, which was really focused on structure prediction. Brian had the idea of combining that with sequence design, kind of like Steve Mayo had done, to do flexible backbone protein design.
In 2003, he and Gautam Dantas had developed
Top7
, which was a protein with a brand new structure that was different from anything in nature. That opened the floodgates. Top7 didn’t do anything, but we thought, “Now we can design new proteins to have all sorts of new functions.”
Dunn:
Where is the field in connecting protein sequences to functions?
Baker:
A lot of what we’re doing, back to the binder design problem, is we start from the structure of a target. With AlphaFold, one can generate structures pretty accurately for a lot of proteins.
Function is important, too, because we want to make things that are going to cure disease. Biology is still really hard. What people don’t understand is that the problem of making a binder to a target is close to getting solved. The real question is what should you make binders to, and there’s a lot of different answers to that.
We’re also designing conditional therapeutics that only should be active at the right time and place in the body. We have all this mechanism design — binding design, conditionality — but the real question is what is the right pair to bring together, and what is the right target to block or agonize? The biology is still a very important part of this that goes beyond design.
Dunn:
If we went back a decade, and I asked you about what you just said — designing binders to targets as a solved problem — that would be astonishing.
Baker:
This all happened in the last five years.
If you look at our recent papers, we’re just about to upload one on making really large numbers of synthetic cytokines by bringing together different pairs of receptors and novel combinations. We have something like 25 binders, 11 of which were designed for that paper. Now it’s about making whole collections of binders to attack a certain problem.
We’ve been working on these physically based methods for designing binders for quite some time. Longxing Cao and Brian Coventry made
this big breakthrough
, where we showed we could design binders to 13 different targets. That was using the old Rosetta, physically based models.
A couple years later, after we developed RFdiffusion, we found we could make binders better and faster than before. We kind of solved the problem in two different ways.
Dunn:
The acceleration of progress in the last few years is remarkable. What are the key drivers of that?
Baker:
As the technologies get better, they feed on each other. My lab’s kind of exploded, there’s so many smart people trying to develop stuff. Someone will make an advance and another person will build on it.
Another part is the application of deep learning to protein design. RFdiffusion and ProteinMPNN, these tools are now being used around the world. I get emails all the time saying we made a great binder with your software.
The other point that sometimes goes unsaid was there was this huge untapped resource in the Protein Data Bank. There were probably tens of billions of dollars put into it over 60 years. Now the AI methods are really kind of tapping what was in there.
Dunn:
When you think of lead optimization, getting something to look more like a drug, how optimistic or skeptical are you that an AI-first approach can tackle that?
Baker:
Let’s say you want to predict whether a compound was going to pass a clinical trial. If we had hundreds of thousands of trials, and we had the compounds, and knew exactly what happened in each of them, I imagine you could train a model that would be pretty effective. We obviously don’t have that data.
I think there are two paths forward: The first is to be clever and to identify proxies that will correlate with long-term success. And then you have those be structural proxies that you can optimize, like we’re going to aim for a certain amount of surface hydrophobicity or something. It’s still going to be a human guess that that property is going to correlate down that way.
The second is to generate the relevant datasets. No entity on Earth can carry out 100,000 clinical trials and collect the data. Big pharma has a lot of internal data on where did different compounds fail in the drug development pipeline. A really interesting thing now is training on that data.
The success of that is going to be determined by how extensive the datasets are. There are efforts within companies like Xaira to generate large internal datasets, and it’ll be interesting to see how those do in developing better drugs.
Dunn:
That’s maybe a holy grail for biopharma for AI. What are the Baker Lab’s holy grail, or holy grails, in the longer term?
Baker:
Being able to design molecular machines like chaperones or motors. This is really kind of futuristic, but I think it’s within reach. We can design catalysts, we can design binding, and now we’re trying to couple binding and catalysis. Designing site-specific proteases.
We’re working toward those now along with really precision medicine, making extremely conditional agonists that only act in very well-defined places. And novel agonists that generate new types of biological activities on specific cell types.
Dunn:
Why has your lab been able to stay so productive for such a long period of time?
Baker:
I have some very strong opinions on how to — well, I can just describe what my philosophy is in running a lab and institute.
It’s based on the idea of a communal brain. Sea slugs have one or two neurons and they can do really simple things. The human brain can do amazing stuff with all the neurons connected.
In my group, the emphasis is on frequent interaction, brainstorming and constant discussion. We have different types of free food every day of the week to try to get people together. If you think of each researcher as a neuron, just trying to maximize the connections.
The second is recruiting people. There are a very large number of people who would like to come to the lab and the institute. That’s the primary selection criteria: You come, you talk to everyone for two days, and everyone votes.
The other thing is I don’t ever go anywhere. I am in every day, walking around, talking to people. I’m just trying to make sure everyone is maximizing connections.
Dunn:
How selective are those votes?
Baker:
Yeah, it’s pretty selective. If you write to me for, say, a postdoc, if you look like a superstar then I ask you to talk to several people in the lab. If they think you’re a superstar, then you get invited.
Dunn:
Is it like getting into Harvard, like five percent?
Baker:
Oh, I don’t know. It’s probably harder. I haven’t really counted.
Dunn:
On startups, there’s a gold-rush mentality for everything AI among VCs. Is that helpful or hurtful to your research?
Baker:
It’s tremendously beneficial.
Dunn:
I imagine there could be tension between radical openness, of ‘Here’s everything I’m working on’ and swapping lab notebooks, versus if you’re starting a company, you might want to say, ‘This is my work and my territory.’
Baker:
That’s a really good point. In the lab, everything is totally open. But at some point if you’re going to develop a new product, you can’t really do that in academic environments.
It gets a bit more complicated for things like DeepMind, which has produced amazing software like AlphaFold. But they’re sort of a company too, so it gets confusing. They release software but don’t make it available. It just creates all this tension. Having a totally open thing that’s hooked onto people starting companies is a nice way to do it.
Dunn:
On open science, your lab has led the way in open-sourcing and publishing constantly. That contrasts with the tech world. OpenAI has largely closed their work. DeepMind, with AlphaFold 3, has teetered on what is and isn’t publicly available. Is there a risk AI bio will grow too closed?
Baker:
I think it’s working pretty well. To DeepMind’s credit, they didn’t release the AlphaFold 3 code, but they published the paper.
The ecosystem is very healthy. I remember the CASP experiment, where protein structure prediction is evaluated, and after DeepMind’s first results were presented there was a worry that big tech was going to dominate structural biology from then on. That’s not what’s happened. There’s no one entity that’s dominating, and I think that’s a good thing.
Protein design really works well in an open environment. The closed environment of a startup or a pharma is really good for taking a slightly more mature idea and developing it to the point where it can really save lives.
Dunn:
It’s been fascinating to see not just DeepMind but stints in protein research from Salesforce, Meta and others. I don’t know if that’s where Salesforce should be spending its time.
Baker:
With tech companies, the large language models are really the thing. If you’re a big tech company and you were investing money in protein folding or protein design, maybe you were getting a little bit behind on the language models.
So now, the companies are retrenching and saying, “Here’s what we need to focus on to survive and the protein stuff was kind of fun, but it was a little bit peripheral.”
Dunn:
On large language models, do you think they’re overrated in biology specifically?
Baker:
There’s probably a little bit too much hype by people who don’t quite know what they’re talking about.
Dunn:
Someone recently put it to me as the “bio-naïve” folks.
Baker:
That’s right, like ChatGPT for biology. That doesn’t really make sense. You ask ChatGPT to program a robot to move around and walk around and it’s hopeless.
Dunn:
To turn to data generation, what are the biggest data gaps?
Baker:
On the pharma side, a lot more data from later in the drug development pipeline. If we go up the food chain, large binding affinity datasets that are really accurate on many different compounds binding to many different proteins. Data on each step in the drug development pipeline, where did compounds fail?
Generating really good datasets is going to be critical for training ML models on them, and it’s going to take a lot of creativity to think about how to generate them.
Dunn:
What makes for a good grad or postgrad research project today in the Baker Lab?
Baker:
They all look a bit on the lunatic fringe. We’re trying to do things that haven’t been solved.
My basic formula is it should be a really important, unsolved project — but there’s a good chance that a really smart, creative, dedicated person could solve it in the next two or three years. I’m aggressively at the forefront.
蛋白降解靶向嵌合体
100 项与 Meta Centre 相关的药物交易
登录后查看更多信息
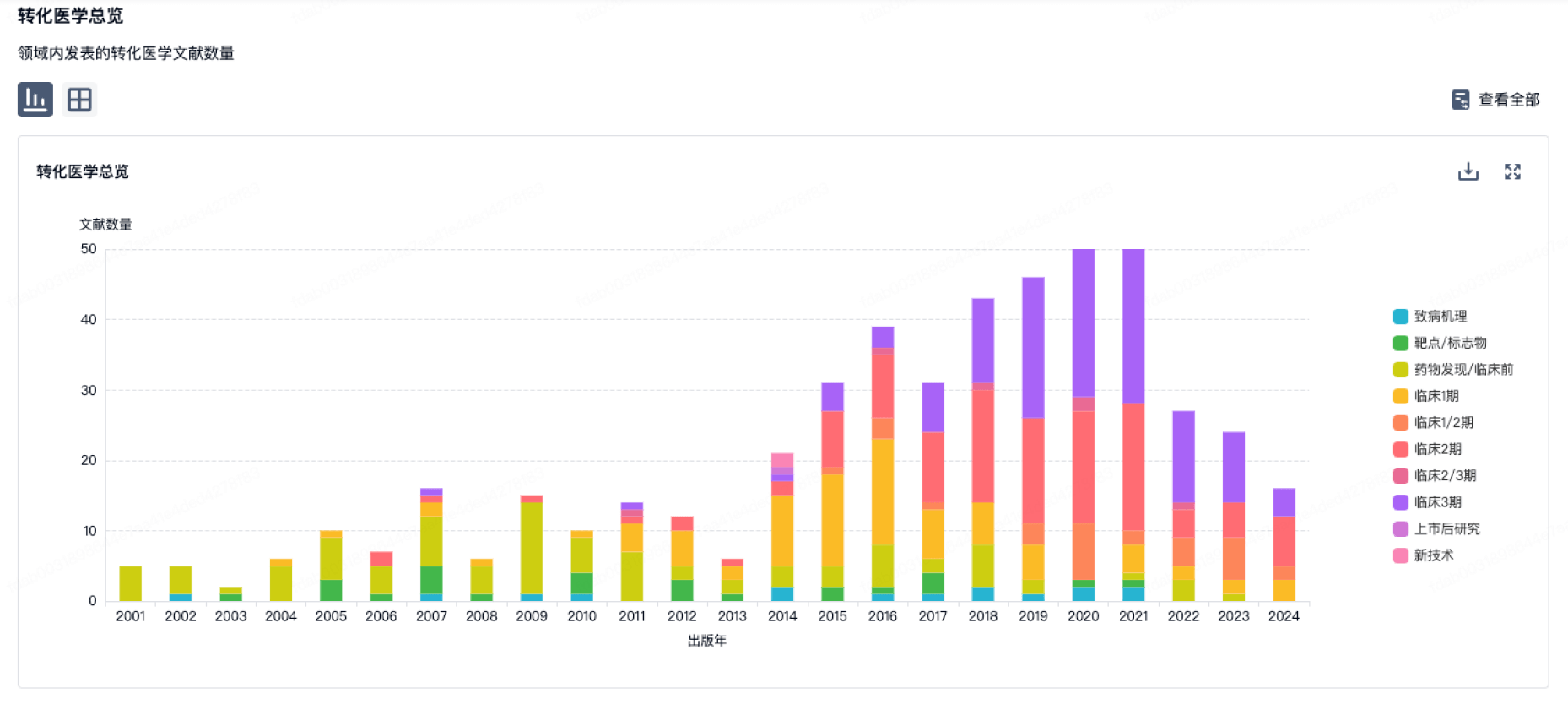
100 项与 Meta Centre 相关的转化医学
登录后查看更多信息
组织架构
使用我们的机构树数据加速您的研究。
登录
或

管线布局
2024年11月20日管线快照
无数据报导
登录后保持更新
药物交易
使用我们的药物交易数据加速您的研究。
登录
或

转化医学
使用我们的转化医学数据加速您的研究。
登录
或
营收
使用 Synapse 探索超过 36 万个组织的财务状况。
登录
或
科研基金(NIH)
访问超过 200 万项资助和基金信息,以提升您的研究之旅。
登录
或

投资
深入了解从初创企业到成熟企业的最新公司投资动态。
登录
或

融资
发掘融资趋势以验证和推进您的投资机会。
登录
或

标准版
¥16800
元/账号/年
新药情报库 | 省钱又好用!
立即使用
来和芽仔聊天吧
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用