更新于:2024-09-19
Shenzhen Shuxin Biotechnology Co., Ltd.
更新于:2024-09-19
概览
关联
100 项与 Shenzhen Shuxin Biotechnology Co., Ltd. 相关的临床结果
登录后查看更多信息
0 项与 Shenzhen Shuxin Biotechnology Co., Ltd. 相关的专利(医药)
登录后查看更多信息
4
项与 Shenzhen Shuxin Biotechnology Co., Ltd. 相关的新闻(医药)2024-06-13
·循因缉药
编者注:本文作者为连续创业者/曙芯生物创始人 曾庆达,2024年5月15日我们曾转载过他一篇文章,他说“下篇再打算写一下DNA合成技术的市场潜力和未来发展格局,以及市场究竟需要什么类型的产品和服务”。
经过我们的不懈“鞭策”,这盘菜终于端了出来。
引言
DNA合成作为生物制造和合成生物的关键底层使能技术,是新一代农业、食品、医药、材料、能源领域发展的基石,其重要性堪比测序技术对基因组学的支撑。
正因为如此,在中美趋近全面对抗的背景下,DNA合成技术及合成仪器,也被美国列入限制出口法案管制。
如同Sanger测序之于法医亲子鉴定,NGS之于目前主流应用,长读长测序之于转录组一般,所有方法学或者平台必须建立在与之匹配的应用场景,以及该应用场景需要取得对应的市场认可度方能成立。
反之则是伪需求,亦或者是昙花一现。
诚然,所有的新品,亦或是新技术,往往会被冠之以“高通量“、”新一代“等名词,这是广告视角;“体验好”、“质量好”、“性价比”,这是客户视角;
本文尝试以不一样的产业视角,来叙述方法学/应用场景/市场空间三者的逻辑关系。
内卷时代的新池塘
熟悉笔者的朋友们都知道,笔者长期从事于基础设施工具商业运营,除了生命科学行业,对于电子制造行业也有一定的涉猎,因此也梳理了一下国内的发展史。
电子制造行业基本上经历了一个从黄金时代到铸铁时代的历程,从最开始的高门槛、高利润到如今高内卷、低利润。
此时,各位生命科学的朋友们,是否觉得对比电子制造行业,我们所处的赛道是不是有些熟悉?或者亦可参考以下文章,来自于小熊猫的创始人,郭昊天博士的知乎专栏,《合成生物学廿年:无尽的创造》。
参考以上的赛道变革以及产业链的变化,结合DNA合成这个领域,是否有相似的潜移默化可以借鉴?
我们都知道,在过去的20年时间里,PCR技术称之为国内分子生物学的基石也不为过,也是在这个时间段里面,柱式合成开启了其黄金时间之旅;然而在新冠后时代,为何大家上下游都突然觉得卷了起来?以下图为例:
方法学不变,应用场景没有拓展空间,市场端又在缩容的背景下,如同一个固定池塘,没有外来活水,而里面鱼却越来越多,最终无非是大鱼吃小鱼,又或者小鱼直接窒息而亡两种局面。
破局点在哪?在活水不进的背景之下,小鱼最好的出路则要么一路吞噬成为大鱼,又或者努力挣扎直接跳出原本的池塘。
这也是在科技技术驱动产业里面经常出现的,打破一种方法学困局的必然是另外一种方法学。
那具体有哪些公司正在做着印刷电路板行业的FPC(新产品)和Quick turn(快交付)类似的事情,以下为实际案例。
呈源生物:专注于基因合成和解码免疫系统的合成生物学和细胞治疗公司:
免疫学当中一类重要的基因是T细胞受体(TCR)。在单细胞测序技术成熟之后,人们可以轻易地从每个样本中获得数千条配对的alpha和beta序列。理论上研究人员可以根据此序列合成全长、配对的TCR基因以研究其功能。但每个TCR可变区的总长度接近1 kb。即便用5毛钱一个碱基的价格计算,合成每个TCR的价格也要500元。合成1000个TCR的价格要50万元。这显然是绝大多数科研单位无法接受的。然而呈源生物开发了超高通量oligo pool定向组装的技术,将合成1个TCR的物料成本降至不到1美元,售价仅7美元(包括NGS测序验证),比传统产品的价格降低了近10倍。此技术也在2024年被《自然-生物技术》报道。如今,呈源生物已经将这一技术应用到任意序列基因的合成。虽然价格的降幅不像TCR基因那样显著,但对于大订单(一次性订购100个以上的1-3kb的基因),售价已经降到0.25 - 0.3人民币。
同时,在行业叠代发展过程中,逐渐也出现了一些如同上述案例中新的池塘。
以下,我们将介绍部分DNA合成下游的“新池塘”。
工程遗传网络和代谢途径
在近几年火热的合成生物学领域,许多研究人员致力于构建和优化遗传网络,以控制细胞行为和化学生产的代谢途径。相关的研发涉及到大量人工基因元件(如启动子、终止子等)的开发和应用,例如化合物X可以特异性诱导细菌A的一些基因表达,鉴定出相应的转录因子和启动子序列就可以应用在其他细菌的遗传、代谢项目中。类似这样对自然界已有的 DNA片段进行排列组合是人工基因元件的一个主要来源。
但由于这些元件和底盘细胞没有经过漫长的共同进化,它们之间可能存在意料之外的相互作用,比如响应化合物X诱导的元件可能会在细菌B里造成细胞毒性,那么可以说这个化合物X诱导系统与宿主B遗传背景之间的正交性不好。
随着合成生物学中工程系统的遗传网络和途径变得越来越复杂,在构建大型多组分系统时,可用的正交组分的数量会变得有限,因此合成生物学领域的大量工作都注重正交性元件的开发,致力于使元件之间、元件与宿主菌之间的相互影响达到最小。
构建人工代谢途径的例子是把克雷伯氏菌的一个长达23KB进行了“面目全非”的重构,涉及到删除非必需基因和非编码序列、去除转录因子、调整密码子,修改大部分调控元件等等。
这样大规模的改造无法通过传统的分子生物学方法完成,完全依赖于基因合成技术。对一种细菌进行系统性的启动子、核糖体结合位点和终止子等元件开发通常需要合成数百到数万种天然或人工设计的序列,这个场景下高通量DNA合成正在成为不可或缺的工具。
全基因组合成和遗传重构
随着测序技术的快速发展,已经完成了对数万个物种的全基因组测序,下一个巨大挑战是破译基因组序列如何发挥作用,从而实现细胞乃至生命各方面的功能。
从合成生物学的角度来看,最好的方式就是从头构建一个基因组,通过设计-构建-测试-学习来研究。
合成基因组学最早可以追溯到1972年人类合成第一个tRNA基因,接下来的几十年里合成了一些基因组在10 KB以内的噬菌体和病毒,直到2010年终于实现了一个标志性成果,即具有化学合成基因组的第一个活体细胞。
不同的研究团队开始了对大肠杆菌和酵母等微生物的基因组重新设计与合成工作,也有一些合成植物和哺乳动物(包括人类)人工染色体的项目正在进行当中。
从应用角度来看,合成基因组具有许多难以替代的作用。
第一,病毒方面,合成病毒可以加速疫苗的生产,在新冠大流行期间做出了重要贡献。
第二,细菌方面,精简了冗余序列和非必要基因的“最小基因组” JCVI-syn3.0细胞被用作细胞生物学和微生物学的基础研究;而经Church 团队重新设计的因组的大肠杆菌“ rE.coli-57 ”仅使用了57个密码子,这样就可以释放了七个密码子以使用非标准氨基酸,从而为合成抗生素和抗肿瘤药物开辟新途径。
最小基因组合成细胞 JCVI-syn3.0
图源:克雷格文特尔研究所 (JCVI)
第三,在酵母方面,合成酵母基因组计划“Sc2.0”开发出了多种新的调控系统,包括光控制和半乳糖控制等,不仅可用于筛选对温度、乙醇、咖啡因、乙酸和木糖高耐受性的酵母菌株,还可用于选择可增加目标化合物产量(如 β-胡萝卜素、紫色素和青霉素)的基因组背景。
以上的这些应用场景涉及到全基因组级别的序列改造,涉及的碱基数往往达到几到几十MB甚至更多,极大地依赖于DNA合成的成本和速度。
酶的定向进化
酶在人类社会无处不在,从日常用的洗衣粉,到食品工业上的酱油醋,还有药物生产和精细化工,酶作为高效、绿色的催化剂广泛应用于各行各业。
天然的酶是自然进化产生的,因此它们的适用环境都是生物体内,很难满足工业化应用场景下的极端环境。比如洗衣粉里的酶可以将污渍中难溶于水的大分子物质分解为小分子从而洗去,但天然的酶很难长期保持活性,而且往往只在比较窄的温度和PH范围内(比如30-37度,pH 6-9)有较好的活性,这就降低了实用性,这样就需要进行延长保存时间,拓宽最适反应条件方面的改造。
酶的定向进化流程上大致分四个步骤:
第一:针对目标功能确立进化起点蛋白,选择一小段区间(通常是活性位点附近),在DNA层面引入大量突变;
第二:将突变基因转入细菌,一一分离得到不同突变的细菌个体,并表达相应的突变体蛋白;
第三:筛选出比进化起点性能更好的目标性能蛋白突变体,并测序得到基因序列;
第四:以获得的最佳突变体作为下一轮进化的起点,开始下一个“突变-筛选”的循环,直至得到预期的蛋白性能。
近年来随着计算机算力的大幅提升和先进算法的涌现,计算机辅助蛋白质设计改造提供了另一种改造酶的思路,尤其是以Alphafold为代表的人工智能技术也被应用于计算机辅助蛋白质设计改造。
通过非随机的方式选取一些关键氨基酸位点,构建“小而精”的突变体库被称为半理性设计,能够有效减少突变体库规模,提高筛选效率。
对任何蛋白进行定向进化都需要引入大量突变这一步骤,传统方法是通过易错PCR等基于PCR扩增的方法来随机产生,这个过程的可控程度较低,很难保证最终得到的突变体库能无偏差地覆盖所有可能的排列组合。
此外,易错PCR很少会产生连续两个碱基的突变,这会进一步减少可能可用的氨基酸;并且可能导致插入和缺失,或引入终止密码子。而高通量基因合成技术恰好可以弥补这些缺憾,可以确保突变库的多样性,几乎不会由于随机因素漏掉任何一种可能性,以更小的工作量和成本,更高的稳定性获得目标性能。
相关成本占比,可参考下表:
时代在变,产业链同样在变。
如同手机,从功能机转入智能机时代,又经历了“中华酷联”大战后,形成了苹果/华为/OPPO等巨头,其代工产业链也逐渐演变为美资->台资->陆资。
可能我们无法预知在生物工业大浪潮中,合成生物/ADC/CGT/mRNA/IVD在未来会如何演变,然而作为其产业链配套,无论扮演何方角色。
但是,至少有3点是值得我们共同努力的,那就是:成本、效率、精度
那么,对于DNA合成下游来说,什么才是好的DNA合成?
共生时代
笔者进入到生命科学这个行业的时候,彼时已经是芯片法检测的末期,大部分的SNP检测已经被PCR所取代;因此美国早年从事芯片法开发的一些公司诸如affymetrix,Full moon逐渐陨落;安捷伦的公司的芯片产线也开始往NGS捕获探针的方式开始转型,这也为后来的Twsit之于高通量合成基因奠定了技术以及产业基础。
可见,方法学也好,应用场景也好,一定是匹配市场真实需求,不断叠代,不断演变的。
而最终决定这一切的,扮演判官角色的,则一定是市场的真实成绩单,或者说,客户到底认为什么是好的。
DNA合成,从客户的角度出发,所谓的好到底指的是什么。
对于工业或者企业级客户而言,往往需求前提是多,通量高,即大量订单的交付需求(如同ICL之于高通量测序);
对于科研级别客户而言,交付体验更为重要;
以上两者共性基础,性价比,即质量不变的情况下,价格更低;
以上,结合起来无非四个字:多快好省。
但是好服务是否一定是好产品或者好模式,不一定。
我们都知道,生命科学领域,大概可分为三类角色:
设备制造商
设备制造商烦恼点在于设备采购以后的更新周期,以及其市场的渗透率;
试剂耗材
试剂耗材商尽管收益于批次可放大,俗称卖水模式的极佳投入产出比,然而这块也是从事的人最多,最卷的领域;
服务商
服务提供商往往会应对五花八门的各种需求,来图定制,耗费大量的人力物力在市场推广,扫楼,售前,售后等繁琐流程;
可以说,各有各的烦恼。
那么,对于初创公司,先努力成为不被吞噬的小鱼才有资格去想接下来的事情。
已经身姿绰约,有点游刃有余的鱼儿们,则要去努力寻找属于自己适合生长的池塘,才是当下的最优解了吧。
其实还有一种可能,就是类似吸盘鱼,又或者是藤壶的角色;牢牢吸附在大鱼的身上,这样最起码在大鱼PK过程中,可以活下来。
这就是我们可能迎来的共生时代,大鱼开疆拓土,共生者牢牢绑定。
对于DNA合成而言,接下来的产品就是逆转铸铁时代、开疆拓土的利器。
END
当然也可以联系我
至此,各位股东星标了么?点赞了么?转发了么?在看了么?谢谢!
近期文章:
标准普尔与普洱
吃下两颗大补丸,华大智造成了爽文主角
聚势谋远 共创共赢 | 寻因生物 & 贝瑞基因开启战略合作
这家公司把NGS和蛋白组学玩出了花
核酸药物
2024-06-13
·循因缉药
本文转载自生命科学产业观察,图表略有修改,已经过原作者同意。
作者:曾庆达
DNA合成作为生物制造和合成生物的关键底层使能技术,是新一代农业、食品、医药、材料、能源领域发展的基石,其重要性堪比测序技术对基因组学的支撑,正因为如此,在中美趋近全面对抗的背景下,DNA合成技术及合成仪器,也被美国列入限制出口法案管制。
众所周知,华大智造的测序仪经历过去十年的发展,已经成为在全球能够和Illumina所抗衡的测序仪平台,能卷国内,也能出海,其核心正是公司从底层对产品力的专注和突破。近年来,DNA合成国内外投资很热,特别是过去三四年国内DNA合成领域,不少企业先后获得数亿元乃至数十亿元的融资金额,然而,相关企业商业化进度延缓,迄今国内也未见技术参数能接近于Twist的产品,如何评价DNA合成企业的团队和技术,成为产业圈及资本圈关注的核心。
一、DNA合成的底层技术与原理
1.1 主流DNA合成产品类型分类
大家对DNA测序了解的可能更多一些,测序就是对未知的DNA序列进行“读”的过程,那相对应的“写”其实就是DNA合成,通俗的讲,就是按照预设的已知的DNA序列顺序,将单个的DNA单元,即脱氧核苷酸,逐个进行人工连接合成DNA链的方法。
当然,DNA概念所涵盖的范围很广,从形式分类上包括单链线性DNA、双链线性DNA、环状DNA等;从长度分类上包括短的几十到几百长度的寡核苷酸(Oligo),长的几百到几千长度的基因(Gene)片段,再到Mb级别的染色体等;从交付形式上分类为单条/管(Oligo或Gene)和多条混合/管(Oligo pool或Gene pool)。
本文主要讨论的是合成服务提供的主流DNA合成产物类型,即寡核苷酸(Oligo)、寡核苷酸池(Oligo pool)和基因(Gene)。
1.2 DNA合成的流程
我们通常说的DNA合成仪直接的合成产物就是Oligo和Oligo pool,通过亚磷酰胺化学合成,包括去封闭、偶联、盖帽和氧化四步循环法,逐一连接核苷酸原料,合成的短的单独可分离的单链寡核苷酸(Oligo)或者混在一起的单链寡核苷酸池(Oligo pool),直接合成的长度通常在300nt以下。
而基因需要在单链寡核苷酸的基础上,通过PCR等分子生物学技术,把短的Oligo经过一次或多次拼接成长的双链DNA,通常长度为几百-几千bp,最后会通过一代Sanger测序或二代NGS的方式进行序列QC验证,为了DNA的稳定性和后续使用方便,通常的交付形式为质粒、穿刺菌或甘油菌,此过程即为基因合成。
后者技术发展的已经很成熟,包括广泛应用的PCA/PCR、Gibson组装、Golden Gate组装技术等,且随着分子酶效率的大幅提升和国产化,其组装成本大幅下降,二代NGS测序技术也在基因序列QC层面进一步压缩了成本,所以目前基因合成的成本大头还是Oligo。
图1 亚磷酰胺三酯法合成原理
1.3 DNA合成成本
以一代合成,完成600bp的小片段基因合成为例,也是常规基因合成流程中最短的基因片段单元,由于需要预留15nt左右的互补同源区,600bp需要拆分成约15条60nt的短Oligo,然后通过PCA/PCR的方式进行组装,克隆到质粒上进行转化培养,最后挑取单克隆进行测序验证。
通常一代柱式合成Oligo成本为0.1元/nt(nmol合成载量,设备试剂原料耗材所决定),即Oligo成本为15*60*0.1=90元,组装成本约为50元,600bp基因长度通常需要3个一代测序反应(客户需要完全正确序列的单克隆质粒),按10元/反应计算,测序费用为30元,即600bp基因总合成费用为90+50+30=170元,Oligo合成占比超五成。
图2 合成600bp小片段基因主要成本(元)
围绕“如何降低合成成本”,目前业内努力的方向,即通过有别于传统一代柱式合成的“微阵列芯片+微流体”技术,包括光化学、电化学和喷墨打印等方式,降低试剂消耗量,采用高通量平行合成样本量均摊的方式降低直合Oligo和Oligo pool的成本。
1.4 DNA合成关键基础指标:合成长度、产量、错误率
说到这里,就讲清楚了DNA合成仪直接合成的产物其实就是Oligo或Oligo pool,那需要什么样的具体指标去衡量合成质量呢,这个就要根据这两种产物类型的应用场景去讨论了,已经归纳汇总到下表。
表1 DNA合成仪产物类型、主要应用场景及合成指标
一般来说,单条交付的Oligo主要是用于引物探针和基因合成这两大块应用,这两种需求对长度要求不高(20-80nt),在保证一定纯度的情况下,主要是看单条的产量和合成错误率。长度和纯度一般是通过HPLC或者PAGE进行QC,对于特殊纯度要求的还需要进行质谱检测;错误率一般是通过把短的Oligo进行基因拼接后测序的方式进行QC。
单条交付的Oligo合成产量不能太低,太低的话,一是不方便后续的纯化操作,稍微一处理就没有了;二是需要进行多循环PCR扩增富集,这个过程中就会引入突变,并且会有碱基偏好性的问题;三是考虑到序列的随机性,单条产量太低,基因组装流程的容错率或者稳定性就很难保证。
综合以上情况,且需要预留足够多(10-50次)的使用次数,单条Oligo合成产量最好能保证到pmol级别。
至于Oligo合成错误率,是基因合成非常重要的指标。因为基因组装的过程采用了聚合酶、连接酶等高保真的分子酶,其错误引入率通常为十万分之一甚至几十万分之一,而用于基因合成的短Oligo大都采用化学法合成,由于每一步化学反应不可能100%,伴随着反应不完全性和可能发生的副反应,随着寡核苷酸链的逐步延长,合成错误率会急剧上升,目前一代柱式合成错误率普遍为0.1%-0.3%,较基因组装过程中分子酶可能引入的错误率高了2-3个数量级,所以Oligo合成错误率是基因合成错误率的绝对来源。
那这个0.1%-0.3%的错误率是什么概念呢,对基因合成来说,高错误率会导致最终基因片段测序QC成本过高,因为客户需要的是完全正确的基因序列,并且每条基因单独交付而不是所有基因序列混合在一起交付,那高错误率就会导致挑单克隆(代表单条基因)送测序的样品数变多。
还是以合成600bp基因为例,如果Oligo合成错误率是0.2%,那单个碱基正确的概率就是99.8%,合成600bp长度基因完全正确的概率就是99.8%600=30%,所以基本上需要一次性挑3-4个克隆进行测序才能保证一批次里有一个完全正确的。相应的高通量DNA合成龙头Twist,其合成错误率宣传为0.05%-0.1%,我们实测结果是0.08%左右,基本一致,那按照以上计算逻辑,单个碱基正确率就是99.92%,合成600bp长度基因完全正确的概率就是99.92%600=62%,所以基本上只需要一次性挑1-2个克隆进行测序就能拿到一个完全正确的,其测序QC成本较一代柱式合成降低一半;
再比如,金斯瑞收购的Customarry,我们假设其合成错误率大概0.5%,单个碱基正确率就是99.5%,合成600bp长度基因完全正确的概率就是99.5%600=5%,这个理论克隆正确率就太低了,如果硬要用来做基因合成的话,就需要每条基因挑20个左右的单克隆进行测序验证才能保证一批次里有一个完全正确的,那这个QC成本就会很高,所以Customarry的合成体系不适合做基因合成,至于为什么会有这么高的错误率,我们稍后再讲。
表2 合成600bp小片段基因,不同错误率对应的理论挑克隆数
对于Oligo pool的产物形式,因为主要的应用场景是sgRNA/shRNA文库、NGS捕获探针文库、DNA存储等,这类需求的主要特点是通量高(万级)、合成长度长(≥90nt),对单条产量(fmol级)和错误率(≤0.5%)要求不高,因为这类需求通常会在序列首尾两端加固定序列,后续可以通过PCR扩增的方式进行富集,而且一般也是用来进行筛选或者捕获实验,较高的错误率一定程度上还能增加筛选库容,对实验效果影响不大,但是对于pool的覆盖度(全部的设计序列至少被测序测到1次)和均一性(90%序列序列reads数/10%序列序列reads数,该比值越低越好,通常要小于10)要求高,这两个核心指标需要通过NSG建库测序的方式进行系统性生信分析比对统计。
二、DNA合成技术的发展历史
DNA合成仪是DNA合成的核心装备。自上世纪九十年代起,以美英为首的西方发达国家基于经典化学合成法原理基础上开始了DNA合成仪的研发与商业化,经历了从第一代柱式合成仪到第二代高通量芯片合成仪的两个关键性时期。
目前第一代柱式合成仪在市场上有多款机型流通,其中接受度较高的代表是Bioautomation-Mermade和Biolyitc-Dr.Oligo系列合成仪。第二代高通量芯片合成仪的出现自2000年起,根据仪器依赖技术原理的不同,大致分为四类高通量合成仪,包括美国LC Sciences公司为代表的光脱保护µParaflo合成仪(合成效率低,错误率高,已被淘汰),美国CustomArray公司为代表的电化学合成技术合成仪(于2017年被金斯瑞生物收购),美国Agilent Technologies及Twist Bioscience公司为代表的喷墨打印合成仪,英国Evonetix公司为代表的集成电路控制合成仪(仅发布技术和专利,成立多年以来未见商业机器发布),以及国内研发起步较早的以华大基因为代表的基于分选的高通量并行合成原理的高通量合成仪。其中,以美国Twist公司的高通量喷墨合成仪综合性能较为突出。
图3 DNA合成仪汇总(a-d)一代柱式合成仪(e-i)二代高通量芯片合成仪
近年来,国内也涌现了一批优秀的新兴企业,技术路径上无一例外的都是采用喷墨打印或者电化学,从侧面也印证了光化学技术路径不适合高质量DNA合成。另外,尽管基于生物酶法合成技术(如TdT酶合成法等)也陆续在欧美国家出现一系列产业布局,但总体仍处于原理验证或商业化早期阶段,而国内对该领域的布局较晚,尚未出现成熟的商业化的设备,本文暂不对生物法合成这块展开讨论,后面有机会再单独分享。这里主要讨论对比技术和商业化成熟的代表性DNA合成:一代柱式合成、二代电化学合成和喷墨打印合成,并汇总对比如下:
表3 代表性DNA合成平台对比
通过以上汇总,我们有几个问题一起深入讨论:
2.1 国产化
一代柱式DNA合成仪因为进入中国较早,且相对技术门槛较低,已经有多家成熟的国产化仿制设备供应商,包括上海仪铂、江苏领坤、北京擎科等,但是商业化成熟的二代高通量合成设备,包括Twist、CustomArray和上表中未列出的Agilent,清一色都是美国公司,且只提供合成服务,不对外出售设备,另外由于中美对抗,高通量DNA合成仪已经受美国限制出口法案管制,中国在这块起步较晚,目前没有成熟的商业化二代高通量DNA合成仪售卖,一花独放不是春,百花齐放春满园,还是需要各位同仁的一起努力。
2.2 应用场景
从合成市场份额占比上看,大致三种应用场景,其份额大概为引物探针:基因合成:Oligo pool = 50%:40%:10%,现有二代高通量合成平台是可以匹配后两者,但是因为单条产量太低,无法满足引物探针需求,传统的一代柱式合成虽然可以覆盖该应用场景,但是有着通量低、成本高的问题。有没有新的二代技术方案,既能满足高通量,又能控制比较低的合成成本呢,这是非常值得大家研究投入的方向。
2.3美国经历了30年的市场发展,为什么最后是喷墨成为了主流?
电化学芯片各个电极(即DNA反应位点)没有物理隔离,合成的时候,整张芯片是完全浸没在反应溶液中,通电后电极上会产生氢离子进行脱保护步骤,但是在溶液状态下,尽管反应体系中会加入碱性缓冲溶液,氢离子也还是会逐渐向周边扩散,就会导致不需要脱保护的DNA也可能会脱除保护基,就会引入错误(大白话就是不该反应的位置反应上了),即便是电极上增加物理隔离,做成“凹”型结构电极,也只是一定程度上控制氢离子扩散,不能完全杜绝,所以从原理讲,电化学技术路径的错误率就会偏高,不适合做基因合成。而且因为电化学芯片电极太小,没有合适的物理隔离结构,其产物形式只能是混合的Oligo pool,无法单独分离,应用场景上会比较受限。
图4 CustomArray电化学合成原理示意图
图5 CustomArray电化学芯片
三、为什么Twist成为高通量合成第一股?
3.1 团队背景与合成基础
创始人&CEO Emily Leproust博士曾在安捷伦科技(喷墨合成鼻祖,20世纪初就实现了商业化)担任DNA合成的芯片表面化学方向的主管(敲黑板划重点了),指导开发了Oligo Library Synthesis技术,是法国里昂工业化学学院工业的化学硕士、美国休斯顿大学有机化学博士。联合创始人&硬件开发副总裁&数据存储总经理Bill Banyai博士层任Complete Genomics的硬件工程副总裁,在硅微纳加工和设备开发方向有深厚技术积累,是密歇根大学的电子科学硕士、亚利桑那大学的光学博士,曾在劳伦斯利弗莫尔国家实验室担任物理学家。另外还有上百人的研发支撑团队,和总计2.53亿美元的融资支持,才能在成立短短5年时间后快速上市,年营收高达2.5亿美元,造就全球高通量合成龙头地位。
图6 Twist高通量喷墨打印DNA合成
图7 Twist高通量超微孔硅基芯片设计专利图
3.2 技术特点
采用喷墨打印+高通量微孔芯片方案,该组合一方面通过喷墨打印实现了超微量加液大幅节省试剂成本,而且是沿用同一代柱式相同的经典亚磷酰胺化学合成体系,通过直接加酸性试剂进行脱保护,较电化学间接产生酸的效果更好,合成效率更高,另一方面微孔的物理隔离设计避免了交叉污染,引入错误更少,同时可以实现单条Oligo或Oligo pool两种产物形式,非常适合高通量基因合成和文库构建。
3.3 Twsit的问题
Twist的喷墨打印芯片通量可达100万条,这个通量有没有意义,大家有没有必要去follow,甚至做更高的通量。
其实这个问题,我们要从两个方面看,一个是市场需求,Twist匹配的应用场景是基因和文库类,100万条Oligo,因为单条0.2fmol,量太少,所以为了后续组装流程稳定,单条至少需要100个拷贝,即100个位点合成同一条Oligo,(即我们可简单理解为后续扩增反应兼容起始引物投入量为至少20fmol)我们按10条Oligo组装一条基因计算,单张芯片100万条Oligo换算下来就是1000条基因,但是一般情况下客户对于基因合成的需求是很分散,不会一次性下单这么多,经常是今天下单几条,明天或者下周下单几条,所以1000条这个通量远超一般需求,为了保证高通量合成成本均摊,就需要凑单或者在饱和率不够的情况下进行生产,这样就会导致交付不及时或者成本失控。
对于文库类应用场景,目前绝大部分文库万级最多十万级通量就足够了,只有像DNA存储这类非常前沿的项目可能会有上百万需求,但是这块应用场景离商业化太远,不是主流需求。二是从成本上看,按照0.5元/bp,1Kb基因就是500元,单张芯片1000条基因就是50万元,基本很少有客户能如此下单;Oligo pool的话,市场价1-2元/条,单张100万条就是100-200万元,即便打半价,也要50-100万,还是同样的问题,这样的客户哪里去找。所以芯片通量设计上,要更多的考虑市场需求,只要能满足90%以上的市场就够了,为了不到10%的用户去投入巨额研发个人感觉不是很明智。
总结而言,我们可以把一台合成仪,一张芯片当作小型的生产线,生产线讲究的是生产良率,产能利用率等综合指标,既要避免甩交期,又要避免产能空转,最后还要结合实际设备耗材造价来综合考虑和设计。
四、与Twist对比,我们还差什么?
最近几年国内做二代高通量合成的公司很多,那到底这个难不难,门槛高不高?对于这个问题,我们还是以Twist为例。Twist在2013年成立,集合如此多优秀的行业顶尖人才,巨额资金投入(2.53亿美金),继承了安捷伦和CG多年的宝贵研发经验,才于2016年开始初步实现商业化,所以说不难肯定是不可能的。难的原因或者行业门槛,要分客观因素和主观因素两个方面。
客观因素:
1)这个跟测序仪不一样,市面上没有可售卖的二代高通量合成设备,就无法短时间内逆向工程;
2)相关专利、文献较少,且大都是芯片设计、流体设计和基因合成流程工艺,没有仪器相关信息,特别是结构设计细节和芯片表面化学处理工艺;
3)国内起步较晚,相关专业人才匮乏。(国内主流生命科学平台多为液相化学)
主观因素:
1)芯片表面化学修饰:因为DNA合成为化学合成过程,芯片表面要经受多轮次长时间的化学试剂浸泡、冲刷,考虑到长链合成时需要足够的化学反应空间以降低位阻效应保证合成效率,芯片表面修饰分子的密度需要精细调整,另外还需要一款可以温和、高效率切断的Linker,以上都需要扎实的化学功底和工艺打磨;
2)合成环境控制:因为fmol级别载量的二代高通量合成相对于nmol级别的一代柱式合成,其反应为超微量体系,对水份、氧含量、VOC含量和试剂残留极其敏感,稍有不慎,合成效率就会受到很大影响,甚至导致合成失败;
3)合成流程优化:需要非常特殊的合成试剂配方,并且对于试剂用量、反应时间、清洗效果都需要严格把控,才能保证高效连接效率和较低的合成错误率。
4)软硬件团队:在化学团队提出需求后,需要经验非常丰富的软硬件团队来实现整机搭建和系统集成,并且与分子、生信团队紧密配合,在拿到测试结果后,在Team Leader带领下进行不断迭代升级。
为什么这么烧钱:
我们还是以测序仪为例,测序仪设计的模块包括但不限于硬件架构、软件算法、光学、流体、酶、试剂、碱基、芯片等模块;而合成仪之于测序仪则可理解为逆向反应,从单碱基合成长片段,其模块组成对比测序仪而言可能只是少了酶的部分,然而其反应更微量,且合成环境为非水相,涉及模块越多,变量就越多,这就不难理解为何合成仪同样需要耗费大量的试验成本。
我们来举一个例子,合成一批次上万条120nt的Oligo pool总共耗费时间:
1)每轮反应大概20分钟,这样从上机到下机的初始产物的合成时长约为2天时间;
2)其后就是氨解,测浓度,跑胶看长度分布,这里又会耗费大约1天时间;
3)建库,上机NGS测序,1-2天时间;
4)测序报告数据分析,1-2天时间
也就是说,我们拿到一次完整的120nt的Oligo pool合成结果,顺利的话大概需要6-7个工作日。
这个时候团队需要根据最终的测序结果,去判断可能存在问题是出自于合成试剂、合成原料、硬件、软件、芯片、合成环境的某一部分或者某多部分的影响。一旦出现判断误差,则不仅是过去7个工作日的实验是无用功,同样会导致下个7个工作日实验是无用功。因此在整个项目管理过程中,无论是从原理机→工程机→商用机所需要的平行测试仪器数量,以及关键变量影响的解决和判断,都需要耗费大量的金钱和时间去不断试错。
毕竟一年只有52周,满打满算可能一台设备最多也只能合成20-30次实验结果,更不要说某些实验结果可能连参考意义都没有,所以高通量DNA合成项目的客观研发周期是很长的,一个好的Team组合或者研发基础,对于加速该项目进度是至关重要的。
综上,高通量DNA合成仪研发中涉及化学、分子、硬件、软件、生信等专业背景团队的通力合作,其中化学又是重中之重,并且由于其反应试剂为易腐蚀、易挥发的有机相而非水相的特殊性,和缺乏可参考借鉴信息的客观因素,一定程度其综合研发难度不亚于测序仪开发。
写在结尾
基于上文所述的历史背景,产业需求以及相关技术特征指标,在1955年剑桥大学Todd教授发明亚磷酰胺四步法以来,在70年的发展之中,目前形成已中美为主导的DNA合成产业格局。
全球基因合成龙头:金斯瑞
全球引物探针龙头为:IDT(丹纳赫收购)
全球高通量合成龙头:Twist
国内引物探针龙头为:生工生物
最后,所有的技术本身,最终都要回归用户层面。客户真实的合成服务需求其实很简单,客户不管你是用一代柱式还是二代合成技术,最终就是要质量好、便宜、交付快,当然服务体验和产品稳定性也是非常重要的。
以常规基因合成(难度序列情况特殊,不在考虑范围)为例,因为每条基因交付前都会经过测序验证,所以质量不是问题,同时基因组装流程已经比较成熟,各大合成服务供应商都差不多,所以交付时间上也相差不大,最后最重要的就是费用问题。前面有提到,Oligo成本占比基因合成超5成,所以谁能实现高通量、低成本、低错误率Oligo合成,谁就可以在基因合成成本上占据优势;引物探针和Oligo pool产品也是一样,因为涉及的后处理流程较少,核心问题还是合成成本。这也就从用户或者市场需求出发,倒逼上游进行高通量合成仪开发,解决行业痛点,解决“生物制造/合成生物学”卡脖子问题。
“一万年太久,只争朝夕”,各位同仁,努力,加油!
下篇再打算写一下DNA合成技术的市场潜力和未来发展格局,以及市场究竟需要什么类型的产品和服务,“多快好省”是主旋律,但市场也需要新东西,后面码字凑全了再分享给各位。
作者:连续创业者/曙芯生物创始人 曾庆达
(连续创业者/曙芯生物创始人 曾庆达)
END
啊对对对对,扫描这货
能联系到我
至此,各位股东星标了么?点赞了么?转发了么?在看了么?谢谢!
近期文章:
Guardant Health营收大增31%之后的隐忧...
14亿美元,我们再一次摸准了Natera的脉!
十年,我想跟肿瘤NGS从业者们谈谈
营收大跌53%,计划裁员,合成生物学龙头梦碎2024?
寡核苷酸核酸药物
2024-05-15
·循因缉药
本文转载自生命科学产业观察,图表略有修改,已经过原作者同意。作者:曾庆达DNA合成作为生物制造和合成生物的关键底层使能技术,是新一代农业、食品、医药、材料、能源领域发展的基石,其重要性堪比测序技术对基因组学的支撑,正因为如此,在中美趋近全面对抗的背景下,DNA合成技术及合成仪器,也被美国列入限制出口法案管制。众所周知,华大智造的测序仪经历过去十年的发展,已经成为在全球能够和Illumina所抗衡的测序仪平台,能卷国内,也能出海,其核心正是公司从底层对产品力的专注和突破。近年来,DNA合成国内外投资很热,特别是过去三四年国内DNA合成领域,不少企业先后获得数亿元乃至数十亿元的融资金额,然而,相关企业商业化进度延缓,迄今国内也未见技术参数能接近于Twist的产品,如何评价DNA合成企业的团队和技术,成为产业圈及资本圈关注的核心。一、DNA合成的底层技术与原理1.1 主流DNA合成产品类型分类大家对DNA测序了解的可能更多一些,测序就是对未知的DNA序列进行“读”的过程,那相对应的“写”其实就是DNA合成,通俗的讲,就是按照预设的已知的DNA序列顺序,将单个的DNA单元,即脱氧核苷酸,逐个进行人工连接合成DNA链的方法。当然,DNA概念所涵盖的范围很广,从形式分类上包括单链线性DNA、双链线性DNA、环状DNA等;从长度分类上包括短的几十到几百长度的寡核苷酸(Oligo),长的几百到几千长度的基因(Gene)片段,再到Mb级别的染色体等;从交付形式上分类为单条/管(Oligo或Gene)和多条混合/管(Oligo pool或Gene pool)。本文主要讨论的是合成服务提供的主流DNA合成产物类型,即寡核苷酸(Oligo)、寡核苷酸池(Oligo pool)和基因(Gene)。1.2 DNA合成的流程我们通常说的DNA合成仪直接的合成产物就是Oligo和Oligo pool,通过亚磷酰胺化学合成,包括去封闭、偶联、盖帽和氧化四步循环法,逐一连接核苷酸原料,合成的短的单独可分离的单链寡核苷酸(Oligo)或者混在一起的单链寡核苷酸池(Oligo pool),直接合成的长度通常在300nt以下。而基因需要在单链寡核苷酸的基础上,通过PCR等分子生物学技术,把短的Oligo经过一次或多次拼接成长的双链DNA,通常长度为几百-几千bp,最后会通过一代Sanger测序或二代NGS的方式进行序列QC验证,为了DNA的稳定性和后续使用方便,通常的交付形式为质粒、穿刺菌或甘油菌,此过程即为基因合成。后者技术发展的已经很成熟,包括广泛应用的PCA/PCR、Gibson组装、Golden Gate组装技术等,且随着分子酶效率的大幅提升和国产化,其组装成本大幅下降,二代NGS测序技术也在基因序列QC层面进一步压缩了成本,所以目前基因合成的成本大头还是Oligo。图1 亚磷酰胺三酯法合成原理1.3 DNA合成成本以一代合成,完成600bp的小片段基因合成为例,也是常规基因合成流程中最短的基因片段单元,由于需要预留15nt左右的互补同源区,600bp需要拆分成约15条60nt的短Oligo,然后通过PCA/PCR的方式进行组装,克隆到质粒上进行转化培养,最后挑取单克隆进行测序验证。通常一代柱式合成Oligo成本为0.1元/nt(nmol合成载量,设备试剂原料耗材所决定),即Oligo成本为15*60*0.1=90元,组装成本约为50元,600bp基因长度通常需要3个一代测序反应(客户需要完全正确序列的单克隆质粒),按10元/反应计算,测序费用为30元,即600bp基因总合成费用为90+50+30=170元,Oligo合成占比超五成。图2 合成600bp小片段基因主要成本(元)围绕“如何降低合成成本”,目前业内努力的方向,即通过有别于传统一代柱式合成的“微阵列芯片+微流体”技术,包括光化学、电化学和喷墨打印等方式,降低试剂消耗量,采用高通量平行合成样本量均摊的方式降低直合Oligo和Oligo pool的成本。1.4 DNA合成关键基础指标:合成长度、产量、错误率说到这里,就讲清楚了DNA合成仪直接合成的产物其实就是Oligo或Oligo pool,那需要什么样的具体指标去衡量合成质量呢,这个就要根据这两种产物类型的应用场景去讨论了,已经归纳汇总到下表。表1 DNA合成仪产物类型、主要应用场景及合成指标一般来说,单条交付的Oligo主要是用于引物探针和基因合成这两大块应用,这两种需求对长度要求不高(20-80nt),在保证一定纯度的情况下,主要是看单条的产量和合成错误率。长度和纯度一般是通过HPLC或者PAGE进行QC,对于特殊纯度要求的还需要进行质谱检测;错误率一般是通过把短的Oligo进行基因拼接后测序的方式进行QC。单条交付的Oligo合成产量不能太低,太低的话,一是不方便后续的纯化操作,稍微一处理就没有了;二是需要进行多循环PCR扩增富集,这个过程中就会引入突变,并且会有碱基偏好性的问题;三是考虑到序列的随机性,单条产量太低,基因组装流程的容错率或者稳定性就很难保证。综合以上情况,且需要预留足够多(10-50次)的使用次数,单条Oligo合成产量最好能保证到pmol级别。至于Oligo合成错误率,是基因合成非常重要的指标。因为基因组装的过程采用了聚合酶、连接酶等高保真的分子酶,其错误引入率通常为十万分之一甚至几十万分之一,而用于基因合成的短Oligo大都采用化学法合成,由于每一步化学反应不可能100%,伴随着反应不完全性和可能发生的副反应,随着寡核苷酸链的逐步延长,合成错误率会急剧上升,目前一代柱式合成错误率普遍为0.1%-0.3%,较基因组装过程中分子酶可能引入的错误率高了2-3个数量级,所以Oligo合成错误率是基因合成错误率的绝对来源。那这个0.1%-0.3%的错误率是什么概念呢,对基因合成来说,高错误率会导致最终基因片段测序QC成本过高,因为客户需要的是完全正确的基因序列,并且每条基因单独交付而不是所有基因序列混合在一起交付,那高错误率就会导致挑单克隆(代表单条基因)送测序的样品数变多。还是以合成600bp基因为例,如果Oligo合成错误率是0.2%,那单个碱基正确的概率就是99.8%,合成600bp长度基因完全正确的概率就是99.8%600=30%,所以基本上需要一次性挑3-4个克隆进行测序才能保证一批次里有一个完全正确的。相应的高通量DNA合成龙头Twist,其合成错误率宣传为0.05%-0.1%,我们实测结果是0.08%左右,基本一致,那按照以上计算逻辑,单个碱基正确率就是99.92%,合成600bp长度基因完全正确的概率就是99.92%600=62%,所以基本上只需要一次性挑1-2个克隆进行测序就能拿到一个完全正确的,其测序QC成本较一代柱式合成降低一半;再比如,金斯瑞收购的Customarry,我们假设其合成错误率大概0.5%,单个碱基正确率就是99.5%,合成600bp长度基因完全正确的概率就是99.5%600=5%,这个理论克隆正确率就太低了,如果硬要用来做基因合成的话,就需要每条基因挑20个左右的单克隆进行测序验证才能保证一批次里有一个完全正确的,那这个QC成本就会很高,所以Customarry的合成体系不适合做基因合成,至于为什么会有这么高的错误率,我们稍后再讲。表2 合成600bp小片段基因,不同错误率对应的理论挑克隆数对于Oligo pool的产物形式,因为主要的应用场景是sgRNA/shRNA文库、NGS捕获探针文库、DNA存储等,这类需求的主要特点是通量高(万级)、合成长度长(≥90nt),对单条产量(fmol级)和错误率(≤0.5%)要求不高,因为这类需求通常会在序列首尾两端加固定序列,后续可以通过PCR扩增的方式进行富集,而且一般也是用来进行筛选或者捕获实验,较高的错误率一定程度上还能增加筛选库容,对实验效果影响不大,但是对于pool的覆盖度(全部的设计序列至少被测序测到1次)和均一性(90%序列序列reads数/10%序列序列reads数,该比值越低越好,通常要小于10)要求高,这两个核心指标需要通过NSG建库测序的方式进行系统性生信分析比对统计。二、DNA合成技术的发展历史DNA合成仪是DNA合成的核心装备。自上世纪九十年代起,以美英为首的西方发达国家基于经典化学合成法原理基础上开始了DNA合成仪的研发与商业化,经历了从第一代柱式合成仪到第二代高通量芯片合成仪的两个关键性时期。目前第一代柱式合成仪在市场上有多款机型流通,其中接受度较高的代表是Bioautomation-Mermade和Biolyitc-Dr.Oligo系列合成仪。第二代高通量芯片合成仪的出现自2000年起,根据仪器依赖技术原理的不同,大致分为四类高通量合成仪,包括美国LC Sciences公司为代表的光脱保护µParaflo合成仪(合成效率低,错误率高,已被淘汰),美国CustomArray公司为代表的电化学合成技术合成仪(于2017年被金斯瑞生物收购),美国Agilent Technologies及Twist Bioscience公司为代表的喷墨打印合成仪,英国Evonetix公司为代表的集成电路控制合成仪(仅发布技术和专利,成立多年以来未见商业机器发布),以及国内研发起步较早的以华大基因为代表的基于分选的高通量并行合成原理的高通量合成仪。其中,以美国Twist公司的高通量喷墨合成仪综合性能较为突出。图3 DNA合成仪汇总(a-d)一代柱式合成仪(e-i)二代高通量芯片合成仪近年来,国内也涌现了一批优秀的新兴企业,技术路径上无一例外的都是采用喷墨打印或者电化学,从侧面也印证了光化学技术路径不适合高质量DNA合成。另外,尽管基于生物酶法合成技术(如TdT酶合成法等)也陆续在欧美国家出现一系列产业布局,但总体仍处于原理验证或商业化早期阶段,而国内对该领域的布局较晚,尚未出现成熟的商业化的设备,本文暂不对生物法合成这块展开讨论,后面有机会再单独分享。这里主要讨论对比技术和商业化成熟的代表性DNA合成:一代柱式合成、二代电化学合成和喷墨打印合成,并汇总对比如下:表3 代表性DNA合成平台对比通过以上汇总,我们有几个问题一起深入讨论:2.1 国产化一代柱式DNA合成仪因为进入中国较早,且相对技术门槛较低,已经有多家成熟的国产化仿制设备供应商,包括上海仪铂、江苏领坤、北京擎科等,但是商业化成熟的二代高通量合成设备,包括Twist、CustomArray和上表中未列出的Agilent,清一色都是美国公司,且只提供合成服务,不对外出售设备,另外由于中美对抗,高通量DNA合成仪已经受美国限制出口法案管制,中国在这块起步较晚,目前没有成熟的商业化二代高通量DNA合成仪售卖,一花独放不是春,百花齐放春满园,还是需要各位同仁的一起努力。2.2 应用场景从合成市场份额占比上看,大致三种应用场景,其份额大概为引物探针:基因合成:Oligo pool = 50%:40%:10%,现有二代高通量合成平台是可以匹配后两者,但是因为单条产量太低,无法满足引物探针需求,传统的一代柱式合成虽然可以覆盖该应用场景,但是有着通量低、成本高的问题。有没有新的二代技术方案,既能满足高通量,又能控制比较低的合成成本呢,这是非常值得大家研究投入的方向。2.3美国经历了30年的市场发展,为什么最后是喷墨成为了主流?电化学芯片各个电极(即DNA反应位点)没有物理隔离,合成的时候,整张芯片是完全浸没在反应溶液中,通电后电极上会产生氢离子进行脱保护步骤,但是在溶液状态下,尽管反应体系中会加入碱性缓冲溶液,氢离子也还是会逐渐向周边扩散,就会导致不需要脱保护的DNA也可能会脱除保护基,就会引入错误(大白话就是不该反应的位置反应上了),即便是电极上增加物理隔离,做成“凹”型结构电极,也只是一定程度上控制氢离子扩散,不能完全杜绝,所以从原理讲,电化学技术路径的错误率就会偏高,不适合做基因合成。而且因为电化学芯片电极太小,没有合适的物理隔离结构,其产物形式只能是混合的Oligo pool,无法单独分离,应用场景上会比较受限。图4 CustomArray电化学合成原理示意图图5 CustomArray电化学芯片三、为什么Twist成为高通量合成第一股?3.1 团队背景与合成基础创始人&CEO Emily Leproust博士曾在安捷伦科技(喷墨合成鼻祖,20世纪初就实现了商业化)担任DNA合成的芯片表面化学方向的主管(敲黑板划重点了),指导开发了Oligo Library Synthesis技术,是法国里昂工业化学学院工业的化学硕士、美国休斯顿大学有机化学博士。联合创始人&硬件开发副总裁&数据存储总经理Bill Banyai博士层任Complete Genomics的硬件工程副总裁,在硅微纳加工和设备开发方向有深厚技术积累,是密歇根大学的电子科学硕士、亚利桑那大学的光学博士,曾在劳伦斯利弗莫尔国家实验室担任物理学家。另外还有上百人的研发支撑团队,和总计2.53亿美元的融资支持,才能在成立短短5年时间后快速上市,年营收高达2.5亿美元,造就全球高通量合成龙头地位。图6 Twist高通量喷墨打印DNA合成图7 Twist高通量超微孔硅基芯片设计专利图3.2 技术特点采用喷墨打印+高通量微孔芯片方案,该组合一方面通过喷墨打印实现了超微量加液大幅节省试剂成本,而且是沿用同一代柱式相同的经典亚磷酰胺化学合成体系,通过直接加酸性试剂进行脱保护,较电化学间接产生酸的效果更好,合成效率更高,另一方面微孔的物理隔离设计避免了交叉污染,引入错误更少,同时可以实现单条Oligo或Oligo pool两种产物形式,非常适合高通量基因合成和文库构建。3.3 Twsit的问题Twist的喷墨打印芯片通量可达100万条,这个通量有没有意义,大家有没有必要去follow,甚至做更高的通量。其实这个问题,我们要从两个方面看,一个是市场需求,Twist匹配的应用场景是基因和文库类,100万条Oligo,因为单条0.2fmol,量太少,所以为了后续组装流程稳定,单条至少需要100个拷贝,即100个位点合成同一条Oligo,(即我们可简单理解为后续扩增反应兼容起始引物投入量为至少20fmol)我们按10条Oligo组装一条基因计算,单张芯片100万条Oligo换算下来就是1000条基因,但是一般情况下客户对于基因合成的需求是很分散,不会一次性下单这么多,经常是今天下单几条,明天或者下周下单几条,所以1000条这个通量远超一般需求,为了保证高通量合成成本均摊,就需要凑单或者在饱和率不够的情况下进行生产,这样就会导致交付不及时或者成本失控。对于文库类应用场景,目前绝大部分文库万级最多十万级通量就足够了,只有像DNA存储这类非常前沿的项目可能会有上百万需求,但是这块应用场景离商业化太远,不是主流需求。二是从成本上看,按照0.5元/bp,1Kb基因就是500元,单张芯片1000条基因就是50万元,基本很少有客户能如此下单;Oligo pool的话,市场价1-2元/条,单张100万条就是100-200万元,即便打半价,也要50-100万,还是同样的问题,这样的客户哪里去找。所以芯片通量设计上,要更多的考虑市场需求,只要能满足90%以上的市场就够了,为了不到10%的用户去投入巨额研发个人感觉不是很明智。总结而言,我们可以把一台合成仪,一张芯片当作小型的生产线,生产线讲究的是生产良率,产能利用率等综合指标,既要避免甩交期,又要避免产能空转,最后还要结合实际设备耗材造价来综合考虑和设计。四、与Twist对比,我们还差什么?最近几年国内做二代高通量合成的公司很多,那到底这个难不难,门槛高不高?对于这个问题,我们还是以Twist为例。Twist在2013年成立,集合如此多优秀的行业顶尖人才,巨额资金投入(2.53亿美金),继承了安捷伦和CG多年的宝贵研发经验,才于2016年开始初步实现商业化,所以说不难肯定是不可能的。难的原因或者行业门槛,要分客观因素和主观因素两个方面。客观因素:1)这个跟测序仪不一样,市面上没有可售卖的二代高通量合成设备,就无法短时间内逆向工程;2)相关专利、文献较少,且大都是芯片设计、流体设计和基因合成流程工艺,没有仪器相关信息,特别是结构设计细节和芯片表面化学处理工艺;3)国内起步较晚,相关专业人才匮乏。(国内主流生命科学平台多为液相化学)主观因素:1)芯片表面化学修饰:因为DNA合成为化学合成过程,芯片表面要经受多轮次长时间的化学试剂浸泡、冲刷,考虑到长链合成时需要足够的化学反应空间以降低位阻效应保证合成效率,芯片表面修饰分子的密度需要精细调整,另外还需要一款可以温和、高效率切断的Linker,以上都需要扎实的化学功底和工艺打磨;2)合成环境控制:因为fmol级别载量的二代高通量合成相对于nmol级别的一代柱式合成,其反应为超微量体系,对水份、氧含量、VOC含量和试剂残留极其敏感,稍有不慎,合成效率就会受到很大影响,甚至导致合成失败;3)合成流程优化:需要非常特殊的合成试剂配方,并且对于试剂用量、反应时间、清洗效果都需要严格把控,才能保证高效连接效率和较低的合成错误率。4)软硬件团队:在化学团队提出需求后,需要经验非常丰富的软硬件团队来实现整机搭建和系统集成,并且与分子、生信团队紧密配合,在拿到测试结果后,在Team Leader带领下进行不断迭代升级。为什么这么烧钱:我们还是以测序仪为例,测序仪设计的模块包括但不限于硬件架构、软件算法、光学、流体、酶、试剂、碱基、芯片等模块;而合成仪之于测序仪则可理解为逆向反应,从单碱基合成长片段,其模块组成对比测序仪而言可能只是少了酶的部分,然而其反应更微量,且合成环境为非水相,涉及模块越多,变量就越多,这就不难理解为何合成仪同样需要耗费大量的试验成本。我们来举一个例子,合成一批次上万条120nt的Oligo pool总共耗费时间:1)每轮反应大概20分钟,这样从上机到下机的初始产物的合成时长约为2天时间;2)其后就是氨解,测浓度,跑胶看长度分布,这里又会耗费大约1天时间;3)建库,上机NGS测序,1-2天时间;4)测序报告数据分析,1-2天时间也就是说,我们拿到一次完整的120nt的Oligo pool合成结果,顺利的话大概需要6-7个工作日。这个时候团队需要根据最终的测序结果,去判断可能存在问题是出自于合成试剂、合成原料、硬件、软件、芯片、合成环境的某一部分或者某多部分的影响。一旦出现判断误差,则不仅是过去7个工作日的实验是无用功,同样会导致下个7个工作日实验是无用功。因此在整个项目管理过程中,无论是从原理机→工程机→商用机所需要的平行测试仪器数量,以及关键变量影响的解决和判断,都需要耗费大量的金钱和时间去不断试错。毕竟一年只有52周,满打满算可能一台设备最多也只能合成20-30次实验结果,更不要说某些实验结果可能连参考意义都没有,所以高通量DNA合成项目的客观研发周期是很长的,一个好的Team组合或者研发基础,对于加速该项目进度是至关重要的。综上,高通量DNA合成仪研发中涉及化学、分子、硬件、软件、生信等专业背景团队的通力合作,其中化学又是重中之重,并且由于其反应试剂为易腐蚀、易挥发的有机相而非水相的特殊性,和缺乏可参考借鉴信息的客观因素,一定程度其综合研发难度不亚于测序仪开发。写在结尾基于上文所述的历史背景,产业需求以及相关技术特征指标,在1955年剑桥大学Todd教授发明亚磷酰胺四步法以来,在70年的发展之中,目前形成已中美为主导的DNA合成产业格局。全球基因合成龙头:金斯瑞全球引物探针龙头为:IDT(丹纳赫收购)全球高通量合成龙头:Twist 国内引物探针龙头为:生工生物最后,所有的技术本身,最终都要回归用户层面。客户真实的合成服务需求其实很简单,客户不管你是用一代柱式还是二代合成技术,最终就是要质量好、便宜、交付快,当然服务体验和产品稳定性也是非常重要的。以常规基因合成(难度序列情况特殊,不在考虑范围)为例,因为每条基因交付前都会经过测序验证,所以质量不是问题,同时基因组装流程已经比较成熟,各大合成服务供应商都差不多,所以交付时间上也相差不大,最后最重要的就是费用问题。前面有提到,Oligo成本占比基因合成超5成,所以谁能实现高通量、低成本、低错误率Oligo合成,谁就可以在基因合成成本上占据优势;引物探针和Oligo pool产品也是一样,因为涉及的后处理流程较少,核心问题还是合成成本。这也就从用户或者市场需求出发,倒逼上游进行高通量合成仪开发,解决行业痛点,解决“生物制造/合成生物学”卡脖子问题。“一万年太久,只争朝夕”,各位同仁,努力,加油!下篇再打算写一下DNA合成技术的市场潜力和未来发展格局,以及市场究竟需要什么类型的产品和服务,“多快好省”是主旋律,但市场也需要新东西,后面码字凑全了再分享给各位。作者:连续创业者/曙芯生物创始人 曾庆达(连续创业者/曙芯生物创始人 曾庆达)END啊对对对对,扫描这货能联系到我至此,各位股东星标了么?点赞了么?转发了么?在看了么?谢谢!近期文章:Guardant Health营收大增31%之后的隐忧...14亿美元,我们再一次摸准了Natera的脉!十年,我想跟肿瘤NGS从业者们谈谈营收大跌53%,计划裁员,合成生物学龙头梦碎2024?
寡核苷酸核酸药物
100 项与 Shenzhen Shuxin Biotechnology Co., Ltd. 相关的药物交易
登录后查看更多信息
100 项与 Shenzhen Shuxin Biotechnology Co., Ltd. 相关的转化医学
登录后查看更多信息
组织架构
使用我们的机构树数据加速您的研究。
登录
或

管线布局
2024年10月06日管线快照
无数据报导
登录后保持更新
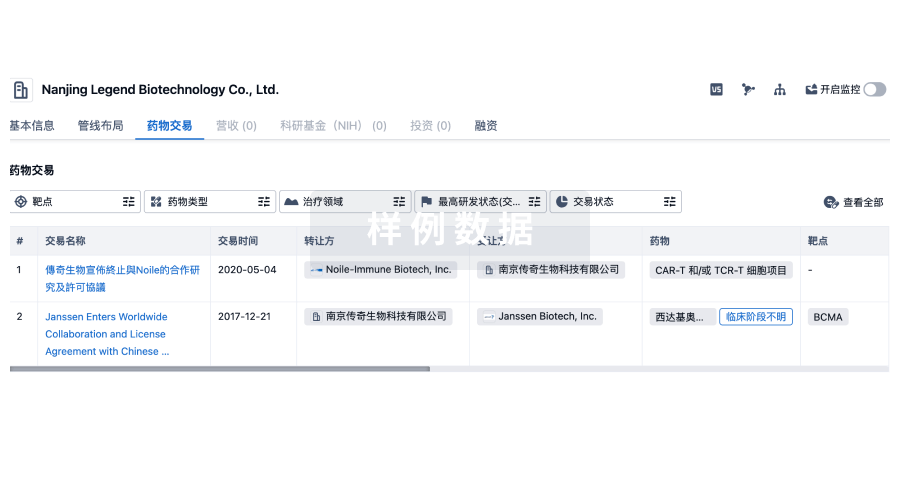
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
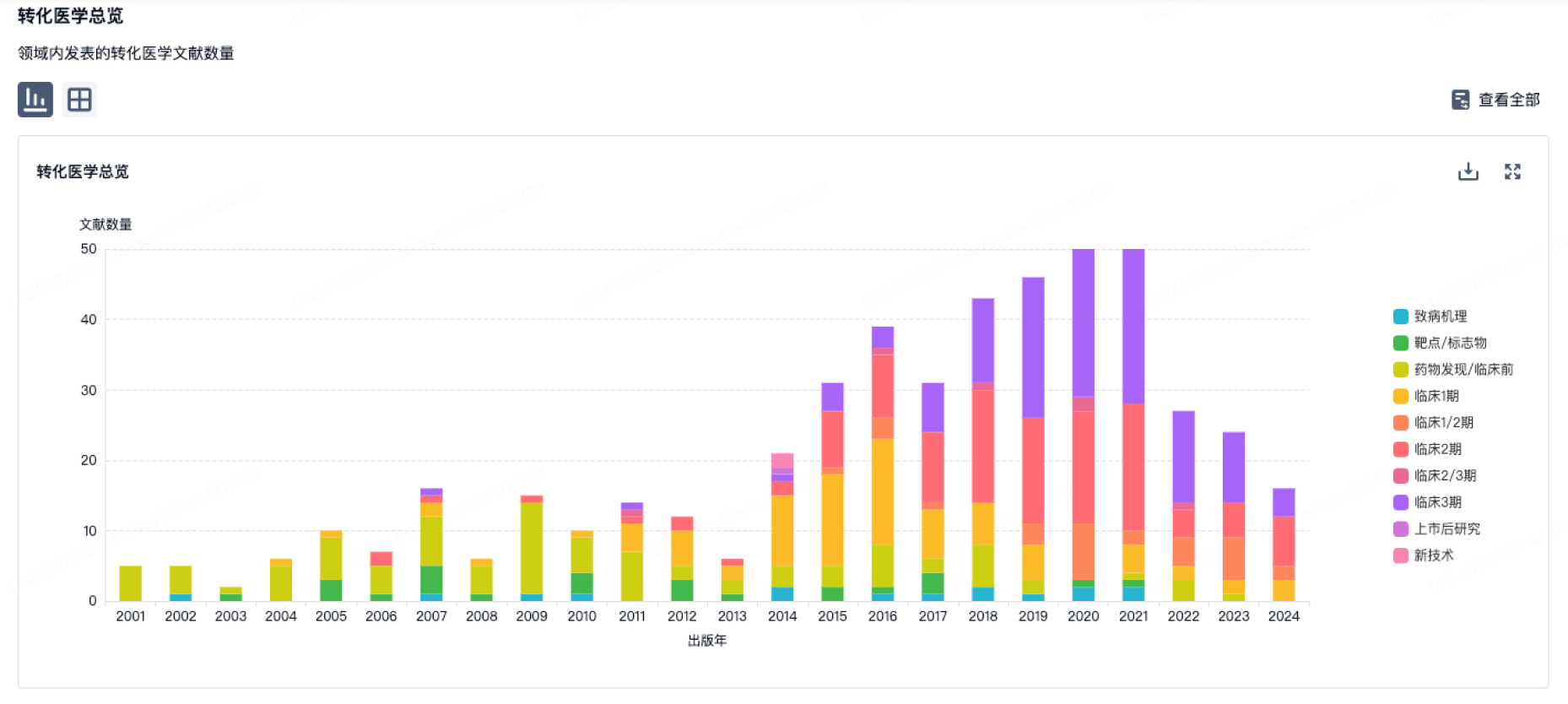
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
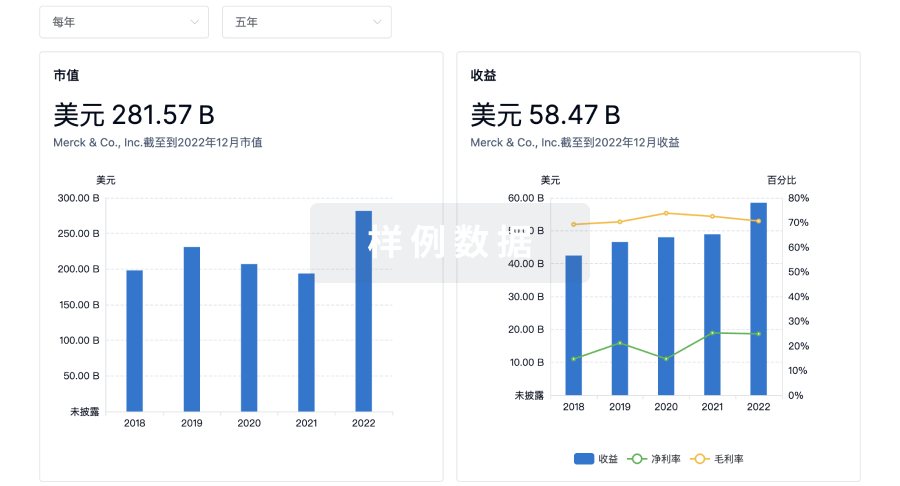
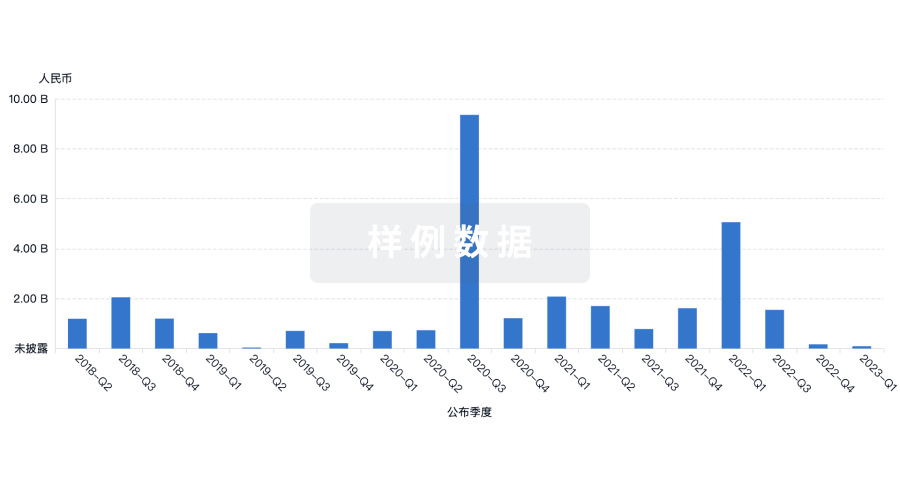
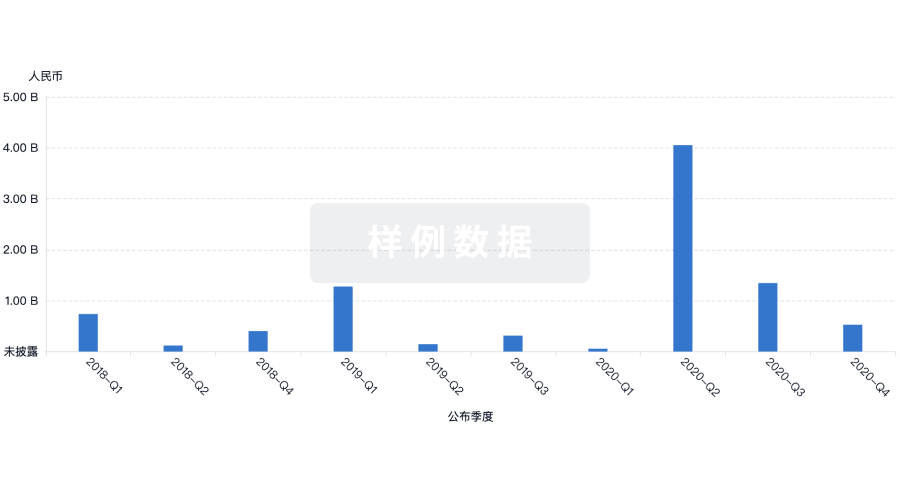
营收
使用 Synapse 探索超过 36 万个组织的财务状况。
登录
或
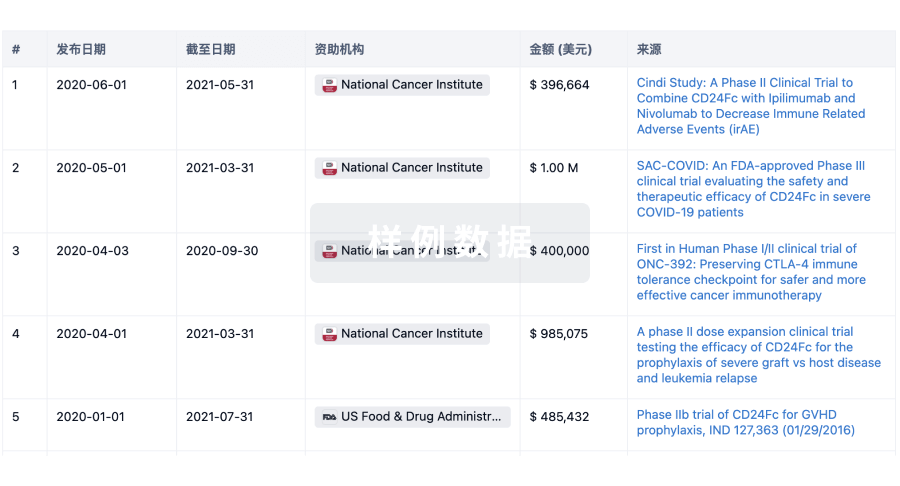
科研基金(NIH)
访问超过 200 万项资助和基金信息,以提升您的研究之旅。
登录
或
投资
深入了解从初创企业到成熟企业的最新公司投资动态。
登录
或
融资
发掘融资趋势以验证和推进您的投资机会。
登录
或
标准版
¥16800
元/账号/年
新药情报库 | 省钱又好用!
立即使用
来和芽仔聊天吧
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用