预约演示
更新于:2025-07-28
Yinfenidone Hydrochloride
盐酸伊非尼酮
更新于:2025-07-28
概要
基本信息
药物类型 小分子化药 |
别名 Yifenidone、HEC-00000585、HEC-585 + [4] |
作用方式 抑制剂 |
作用机制 TGF-α抑制剂(转化生长因子α抑制剂)、TGF-β抑制剂(转化生长因子β抑制剂) |
非在研适应症- |
原研机构 |
在研机构 |
非在研机构- |
权益机构- |
最高研发阶段临床3期 |
首次获批日期- |
最高研发阶段(中国)临床3期 |
特殊审评孤儿药 (美国) |
登录后查看时间轴
关联
10
项与 盐酸伊非尼酮 相关的临床试验NCT07082842
A Multicenter, Parallel, Randomized, Placebo (Double-blind) and Pirfenidone (Open-label) Controlled Phase III Clinical Trial Evaluating the Efficacy and Safety of HEC585 Tablets in Patients With Idiopathic Pulmonary Fibrosis (IPF)
NCT05139719
A Phase IIb, Multi-center, Randomized, Double Blinded, Placebo-controlled, Parallel-group Study to Evaluate the Efficacy and Safety of HEC585 Tablets in Patients With Progressive Fibrosing Interstitial Lung Disease
NCT05468346
Clinical Trial of Absorption, Metabolism and Excretion of [14C]-HEC585 in Chinese Adult Male Healthy Subjects
100 项与 盐酸伊非尼酮 相关的临床结果
登录后查看更多信息
100 项与 盐酸伊非尼酮 相关的转化医学
登录后查看更多信息
100 项与 盐酸伊非尼酮 相关的专利(医药)
登录后查看更多信息
1
项与 盐酸伊非尼酮 相关的文献(医药)Biomedicines
Deep Learning-Based Drug Compounds Discovery for Gynecomastia
Article
作者: Kim, Byeong Seop ; Zhu, Mengyu ; Tang, Yuxi ; Pan, Yuyan ; Lu, Yeheng ; Zeng, Junhao ; Chen, Zhiwei
Background: Gynecomastia, caused by an estrogen–testosterone imbalance, affects males across various age groups. With unclear mechanisms and no approved drugs, the condition underscores the need for efficient, innovative treatment strategies. Methods: This study utilized deep learning-based computational methods to discover potential drug compounds for gynecomastia. To identify genes and pathways associated with gynecomastia, initial analyses included text mining, biological process exploration, pathway enrichment and protein–protein interaction (PPI) network construction. Subsequently, drug–target interactions (DTIs) were examined to identify potential therapeutic compounds. The DeepPurpose toolkit was employed to predict interactions between these candidate drugs and gene targets, prioritizing compounds based on their predicted binding affinities. Results: Text mining identified 177 genes associated with gynecomastia. Gene Ontology (GO) biological process and Kyoto Encyclopedia of Genes and Genomes (KEGG) pathway analyses identified critical genes and pathways, with notable involvement in signal transduction, cell proliferation and steroid hormone biosynthesis. PPI network analysis highlighted 10 crucial genes, such as IGF1, TGFB1 and AR. DTI analysis and DeepPurpose predictions identified 12 potential drugs, including conteltinib, yifenidone and vosilasarm, with high predicted binding affinities to the target genes. Conclusions: The study successfully identified potential drug compounds for gynecomastia using a deep learning-based approach. The findings highlight the effectiveness of combining text mining and artificial intelligence in drug discovery. This innovative method provides a new avenue for developing specific treatments for gynecomastia and underscores the need for further experimental validation and optimization of prediction models to support novel drug development.
100 项与 盐酸伊非尼酮 相关的药物交易
登录后查看更多信息
研发状态
10 条进展最快的记录, 后查看更多信息
登录
| 适应症 | 最高研发状态 | 国家/地区 | 公司 | 日期 |
|---|---|---|---|---|
| 特发性肺纤维化 | 临床3期 | 中国 | 2025-07-28 | |
| 进行性纤维化间质性肺病 | 临床2期 | 中国 | 2023-02-06 | |
| 肝硬化 | 临床申请 | 中国 | 2022-07-20 |
登录后查看更多信息
临床结果
临床结果
适应症
分期
评价
查看全部结果
登录后查看更多信息
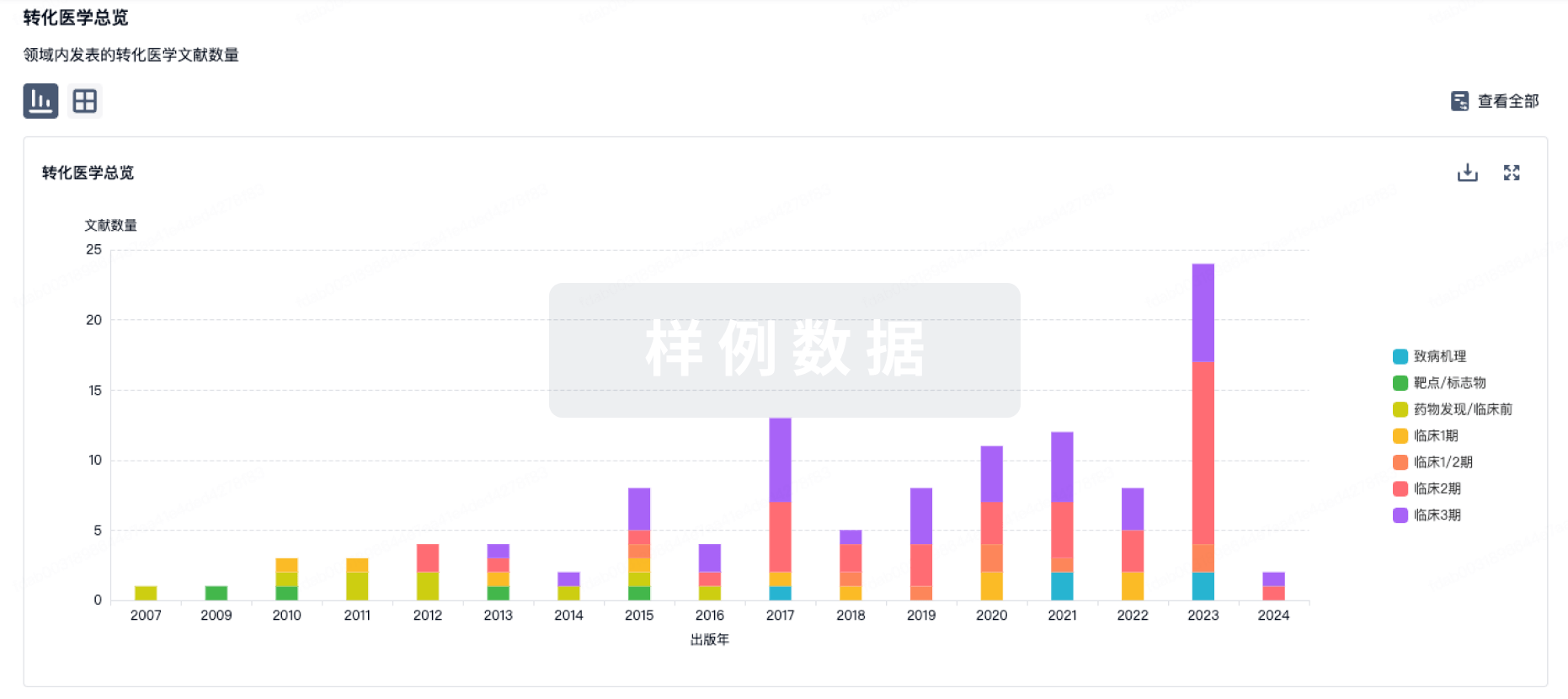
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
核心专利
使用我们的核心专利数据促进您的研究。
登录
或
临床分析
紧跟全球注册中心的最新临床试验。
登录
或
批准
利用最新的监管批准信息加速您的研究。
登录
或
特殊审评
只需点击几下即可了解关键药物信息。
登录
或
生物医药百科问答
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用